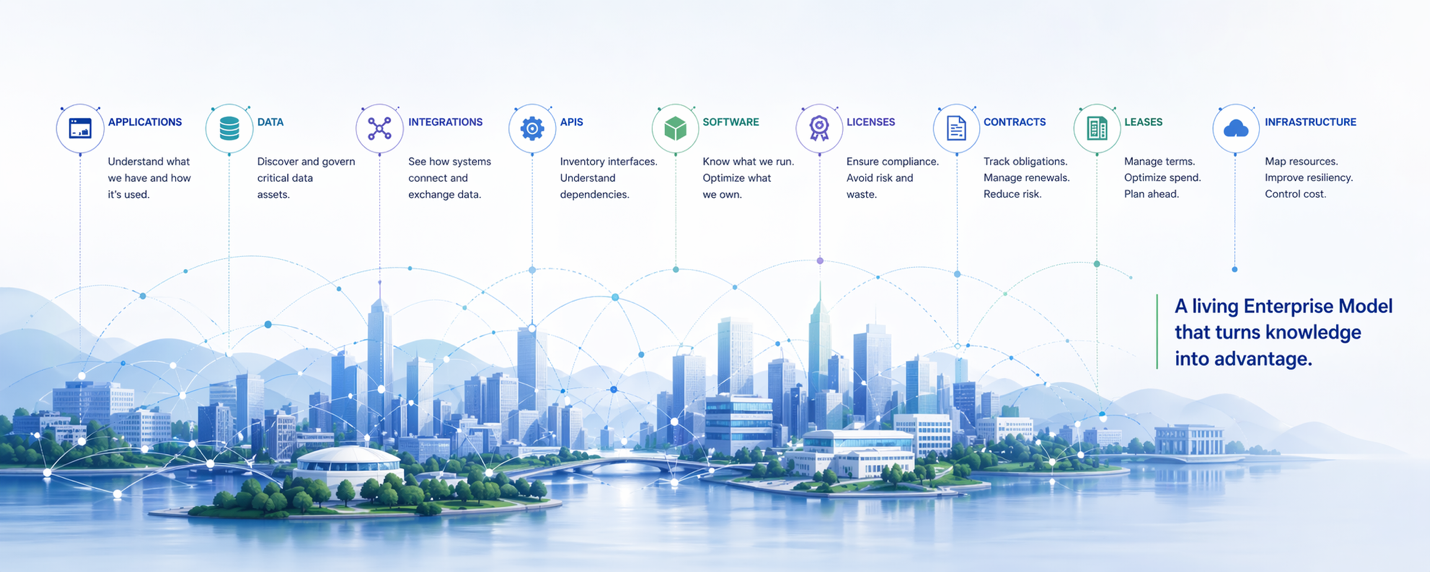
Using AI to Build and Maintain Enterprise Inventories and Models
Enterprise inventories are only as valuable as they are accurate and current. Building and maintaining them has historically been prohibitively expensive — requiring large teams to manually read documents, interpret diagrams, reconcile conflicting sources, and keep records current as the enterprise changes. Artificial intelligence changes that equation fundamentally. This article describes the types of documents you can feed to AI and the work AI can perform to help with the creation, relationship mapping, and maintenance of enterprise inventories and, ultimately, enterprise models.
Author: Frank Guerino
From Why to How
A companion article in this series — “What You Don’t Know About Your Own Enterprise Is Costing You” — made the case for why enterprise inventories are critical management assets. It described the eighteen-plus inventory types that together form the Enterprise Model, explained the executive decision-making capabilities those inventories unlock, and established that organizations without a maintained Enterprise Model spend their time reacting: scrambling to assemble data in the middle of incidents, audits, and negotiations, and surrendering leverage at precisely the moments when it matters most.
The challenge has always been building and maintaining those inventories at scale. The volume of artifacts that describe an enterprise — architecture documents, engineering diagrams, contracts, specifications, source code — is vast. The data within those artifacts is heterogeneous, inconsistently structured, and spread across organizational and system boundaries. And the enterprise changes continuously: new systems are built, old ones retire, integrations are added and modified, contracts are renegotiated. Any inventory program that depends on manual effort to keep pace with that rate of change will fall behind.
Artificial intelligence addresses this challenge directly — not by replacing human judgment but by dramatically reducing the cost and effort of the work that feeds it. This article describes how.
What AI Can Read
The starting point for any AI-assisted inventory program is the artifacts that already exist in the organization. AI does not require structured input, purpose-built data feeds, or specially prepared documents. It can read what the organization already produces, in the formats it already uses. The range of artifacts AI can process as inventory sources is broad:
Architecture diagrams and solution design documents. Solutions architecture diagrams, reference architecture documents, context diagrams, and component diagrams describe the systems in the enterprise, the integrations between them, and the data flows that connect them. These are among the richest sources of Application, Integration, and Data Inventory content available — and they require no preparation before being fed to AI.
Engineering and technical design documents. Low-level design documents, technical specifications, API design documents, database schema documents, and infrastructure design documents describe the implementation layer of the technology estate. They surface asset attributes — technology stack, deployment configuration, performance characteristics, data models — that architecture-level documents do not capture.
Operational documents. Runbooks, process documents, configuration guides, standard operating procedures, and incident response playbooks describe how systems behave in operation. They surface integration dependencies, configuration parameters, and process-to-system mappings that are not captured in design documents.
Contracts. Software license agreements, SaaS subscription agreements, hardware leases, managed service contracts, and data processing agreements contain asset information that exists nowhere else in the enterprise: the licensed product, the entitlement quantity and metric, the financial terms, the renewal date, the termination notice window, and the contractual obligations the organization has accepted. AI can read contracts and extract this information directly into License, Subscription, Contract, and Lease Inventories.
API specifications. OpenAPI, WSDL, AsyncAPI, and GraphQL schema documents formally describe the interfaces systems expose and consume. They are the most precise source of API and Integration Inventory content available, because they describe interfaces as they are actually implemented rather than as they were intended to be implemented.
Infrastructure-as-code. Terraform configurations, CloudFormation templates, Kubernetes manifests, Ansible playbooks, and similar infrastructure definition files describe the actual infrastructure provisioned to support applications and workloads. They are a ground-truth source for Cloud Resource and Hardware Infrastructure Inventory content.
Source code. The most authoritative source available. Source code describes what was actually built — not what was intended, not what was documented, and not what was designed. AI reading a codebase can identify the actual integrations a service exposes and consumes, the databases it connects to, the external services it calls, the data entities it creates and modifies, and the dependencies it carries. Source code surfaces what every other artifact type misses: the undocumented, the unofficial, and the forgotten.
The practical implication is significant: an organization does not need to create new artifacts or restructure existing ones to begin an AI-assisted inventory program. The raw material is already there. The question is how to apply AI to it systematically.
A Better Approach: Natural Language Rules Instead of Code
Before describing what AI can do with these artifacts, it is worth addressing how — because the answer is qualitatively different from what traditional tools require.
The conventional approach to extracting and transforming data from heterogeneous sources at scale is traditional tooling: ETL and ELT pipelines, data integration platforms, custom-built extraction scripts and transformation programs. These tools are capable, and they have been the standard answer to this class of problem for decades. But they carry a cost that is often underestimated: they require software development. Every new source type requires engineering. Every new transformation rule requires code. Every change to a source schema requires a development cycle. Every edge case requires a programmer to anticipate it and handle it explicitly. The tooling does exactly what it was programmed to do — and nothing more. It cannot infer. It cannot reason. It cannot handle the unstructured, context-dependent content of architecture documents, contracts, and source code without significant preprocessing engineering that is itself a non-trivial development effort.
The result is that traditional tooling trades one expensive problem — manual human effort — for a different expensive problem: a software development program that must be maintained, adapted, and extended as the enterprise and its artifact landscape evolve. For most organizations, that cost has been as prohibitive as the manual alternative.
AI with Natural Language Rules changes this entirely. Instead of writing code, subject matter experts write instructions in plain language that describe what they want AI to do. These Natural Language Rules — NLRs — are readable by anyone, writable by anyone with domain knowledge, and adaptable in minutes rather than sprint cycles. An enterprise architect writes the extraction rules for architecture diagrams. A procurement manager writes the cleansing rules for contract data. A compliance officer writes the reconciliation rules for regulatory obligations. None of them needs to engage a development team or write a line of code.
Example Natural Language Rules: "From each architecture diagram, identify every system or application depicted as a named box or component, and extract its name, any labels indicating its type (application, database, service, platform), and every connection line to other components as an integration relationship." And: "When the same system appears in multiple diagrams under slightly different names (e.g., 'Auth Service', 'Authentication Service', 'AuthSvc'), treat them as the same asset and use the most fully-spelled-out name as the canonical form."
Because AI reasons rather than merely executes, the same NLR handles variation in source format, naming convention, and structure that would require separate code paths in a traditional tool. A single extraction rule works across dozens of architecture diagrams that each use slightly different notation styles. A single cleansing rule resolves naming inconsistencies across sources that a pattern-matching script would never generalize to. The rules express intent; AI determines how to apply that intent to whatever it encounters.
This is the foundational shift: the pipeline described in this article does not require a software development project. It requires subject matter experts who understand the inventories and the rules that should govern them — which the organization already has. NLRs are their instrument.
Five Functions AI Performs — and What They Would Cost Without It
What follows describes five functions that, performed by human analysts using traditional tooling, would require significant teams, substantial development investment, and months of elapsed time — and would still produce results of uneven quality that begin decaying the moment they are complete. Performed by AI with NLRs, the same functions run continuously, cost a fraction of the equivalent human and tooling effort, and produce more consistent output because AI applies the same rules the same way every time — without fatigue, without the gaps caused by staff turnover, and without the tribal knowledge dependencies that make manual inventory programs fragile. Each function corresponds to a stage in the pipeline. Together they transform raw enterprise artifacts into a governed, relationship-rich Enterprise Model.
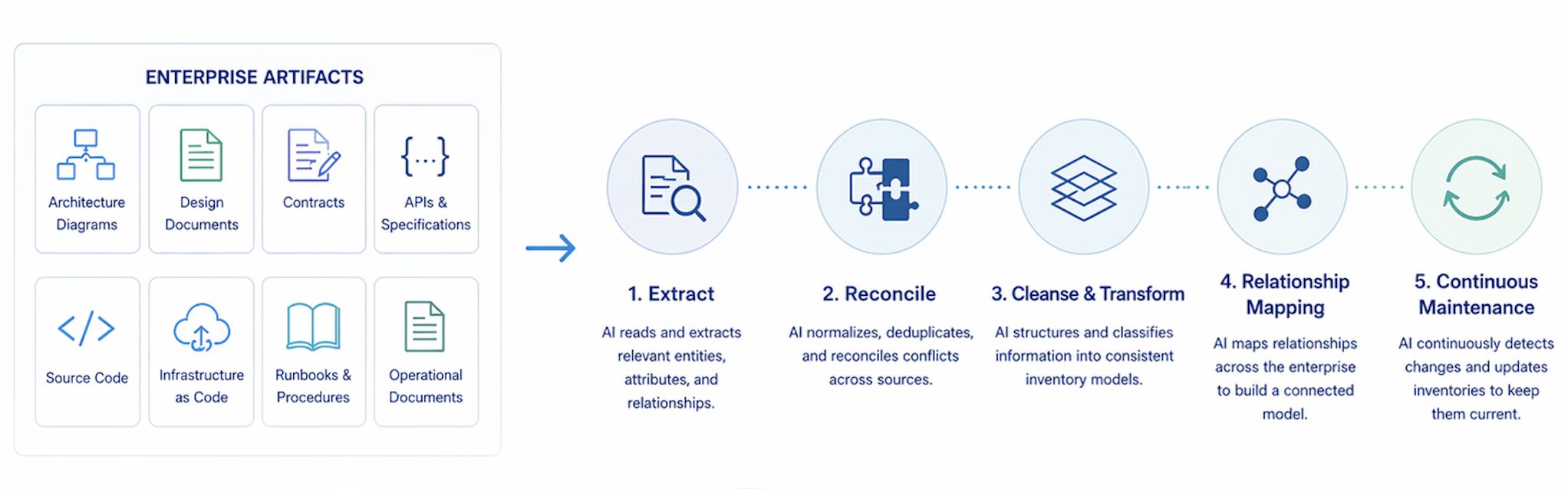
Stage 1: Extract
Extraction is the process of reading source artifacts and identifying the assets and relationships they describe. AI reads an architecture diagram and identifies every system, application, integration, data flow, and dependency depicted. It reads a contract and extracts the licensed product, entitlement terms, financial obligations, renewal date, and termination provisions. It reads a runbook and identifies the systems involved in a process and the sequence in which they interact. It reads source code and surfaces the actual endpoints a service exposes, the databases it connects to, the external APIs it calls, and the data entities it creates and modifies.
The human equivalent: a skilled analyst reading a 40-page solutions architecture document, manually identifying every asset and relationship, and entering each into an inventory system takes several hours per document. Across hundreds of documents, with multiple reviewers of varying consistency, the effort is measured in person-months and the output quality varies with the skill and attention of each individual reviewer. AI performs the same extraction in seconds, at the same quality, for every document.
Example NLR — Extract: "Read this solutions architecture document. For each system, application, service, or platform identified, create an extraction record capturing its name, type, and any described owner or team. For each connection or data flow between two systems, create an integration record capturing the source system, target system, direction of data flow, and any described protocol or pattern."
Stage 2: Reconcile
Reconciliation is the process of comparing extracted findings against existing inventory records to surface discrepancies. AI compares what a newly processed architecture document says exists against what the current Application and Integration Inventories say exists, and identifies three classes of discrepancy: gaps — assets found in the document that have no corresponding inventory record; contradictions — assets described differently across two or more sources; and orphans — inventory records that have no corresponding evidence in any source artifact and may represent retired or misdocumented assets.
The output of reconciliation is not corrections. It is a prioritized, confidence-scored set of candidate discrepancies for human review. High-confidence gaps — an application described in three separate architecture documents that has no inventory record — are surfaced first. Low-confidence discrepancies — a naming variation that might be a different system or might be a variant name for an existing one — are flagged for human judgment.
The human and traditional tooling equivalent: reconciling inventory data across three conflicting source systems, at enterprise scale, is the kind of work that consumes entire analyst teams for months and is never truly complete. Traditional ETL tooling can automate record matching against defined keys and rules, but it cannot reason about ambiguous cases, handle unstructured source content, or identify orphans that exist only by their absence from any evidence source. AI handles all three.
Example NLR — Reconcile: "Compare the applications identified in this architecture diagram against the current Application Inventory. For any application in the diagram that does not have a matching record in the inventory, flag it as a gap with high confidence. For any application in the diagram whose name does not exactly match an inventory record but is likely the same system, flag it as a candidate match with the confidence level and your reasoning. For any inventory record in the Application Inventory that does not appear in any of the last five architecture documents processed, flag it as a potential orphan for human review."
Stage 3: Cleanse & Transform
Cleansing and transformation address the data quality problems that extraction and reconciliation surface. AI normalizes heterogeneous representations into a common schema: resolving naming inconsistencies across sources, filling inferrable gaps with confidence-scored proposals, correcting values that are demonstrably wrong based on contextual evidence, and converting data from the format of the source artifact into the format of the governed inventory.
The cleansing and transformation function is where AI’s reasoning capability delivers its most distinctive value. Traditional ETL tooling can apply deterministic transformation rules — replace this string with that string, convert this date format to that date format — but it cannot infer a missing value from context, recognize that three different strings refer to the same product, or propose a canonical form for a set of variants it has never seen before. AI can do all three, and it does so with confidence scoring so that human reviewers can focus their attention on the proposals where uncertainty is highest while high-confidence normalizations are applied automatically within defined governance rules.
Example NLR — Cleanse & Transform: "When the same software product appears in the inventory under multiple name variants (e.g., 'MS SQL Server 2019', 'MSSQL', 'Microsoft SQL Server', 'SQL Server 2019'), identify them as the same product and propose 'Microsoft SQL Server 2019' as the canonical name. Assign a confidence score to each proposed normalization. For any application record missing its business owner field, infer the most likely owner from the organizational context described in the source documents where the application appears, and propose it with a confidence score and your reasoning."
Stage 4: Create & Populate
Create & Populate is the stage at which AI-assisted findings become authoritative inventory data. AI formats the cleansed and transformed extraction results as proposed new inventory records or proposed updates to existing records, structured to the governed schema and ready for human review and approval before commitment to the inventory system.
This is the human governance checkpoint in the pipeline. The stages before it are AI-driven, with human review of exceptions. This stage requires human sign-off before the results are committed — because creating or updating an authoritative inventory record is a consequential action that carries organizational accountability. The AI’s role is to do all of the preparation work so that the human reviewer is making a confirmation decision rather than a data-gathering decision. The reviewer reads a fully-formed proposed record, with provenance — which source artifacts the data was drawn from — and a confidence score, and approves, rejects, or modifies it.
In steady state, after the initial inventory build, each pipeline run produces not a full rebuild but a delta: a set of proposed additions, updates, and deletions based on newly processed artifacts or changes detected in previously processed ones. This is the delta management function that makes continuous maintenance tractable. The pipeline runs on a defined schedule — weekly, daily, or event-triggered when a new architecture document is published or a contract is executed — and produces a manageable review queue rather than a months-long project.
Example NLR — Create & Populate: "For each gap identified in the reconciliation stage that has a confidence score of 80% or higher, generate a proposed new Application Inventory record populated with all attributes extractable from the source documents. Include the list of source documents used to populate each field, and flag any field where the value was inferred rather than explicitly stated. Format the proposed record to the Application Inventory schema and submit it to the human review queue."
Stage 5: Relate
Relate is the function that transforms a collection of populated inventories into an Enterprise Model. AI identifies and proposes the relationships between inventory records — within and across inventory domains — that give the model its analytical power. Which application supports which business capability. Which integration connects which systems and carries which data entities. Which contract governs which vendor relationship and covers which licensed products. Which license entitles deployment of which software on which infrastructure components. Which business process depends on which applications and produces which data.
These relationships are the edges of the knowledge graph described in the companion article. Without them, the inventories are populated nodes with no connections — useful for answering questions about individual assets but incapable of supporting the multi-hop traversal queries that executive leadership depends on: which systems would be affected by a vendor exit, what is the fully-loaded cost of a business capability, which applications process regulated data and have a contract expiring in the next ninety days.
Relationship inference at enterprise scale is the function most clearly beyond the reach of traditional tooling. ETL pipelines can join records on defined keys. They cannot infer that an application described in an architecture document as the “claims processing platform” is the same as the application in the inventory registered as “ClaimsEngine v4” — and that both map to the Claims Processing capability in the Business Capability Inventory. AI can make that inference, propose the relationship with a confidence score and its reasoning, and submit it for human confirmation.
Example NLR — Relate: "For each application in the Application Inventory, identify the business capabilities in the Business Capability Inventory that it most likely supports based on its name, description, and the architecture documents it appears in. Propose a capability mapping for each application, with a confidence score and the evidence from source documents that supports the mapping. For any application that cannot be confidently mapped to any capability, flag it for human review."
Source Code as Ground Truth
Every artifact type described in this article — architecture diagrams, engineering documents, contracts, API specifications — describes the enterprise as it was intended to be built or as it was understood at the time of writing. Source code describes the enterprise as it actually exists. That distinction matters more than it might initially appear.
In any large enterprise with a significant history, there is a gap between documented intent and implemented reality. Integrations exist in production that were never added to any architecture diagram. Dependencies were introduced during development that were never reflected in any design document. APIs were added to support a short-term need and never cataloged. Data stores were connected to systems that were not supposed to access them. Configuration changes were made under operational pressure and never documented. None of this is visible in any artifact type other than the code itself.
AI reading a codebase can surface what every other artifact misses:
-
Undocumented integrations — service calls to external systems that appear nowhere in any architecture or design document
-
Deprecated dependencies still in active use — libraries, frameworks, or services that are end-of-life but remain in the dependency tree
-
APIs exposed but never cataloged — endpoints that are live in production and potentially accessible to consumers, with no corresponding entry in the API Inventory
-
Data stores connected but unrecorded — database connections in the code that do not appear in any integration or data inventory
-
Configuration-as-code inventory data — infrastructure definitions, environment configurations, and deployment manifests that describe the actual provisioned state of the infrastructure estate
The practical implication is that source code analysis should be the final validation layer for any inventory domain that involves system behavior or infrastructure state. Architecture documents tell you what was designed. Source code tells you what was built. The delta between them is an inventory gap — and in most large enterprises, that delta is substantial.
Source code analysis is also where the NLR approach delivers some of its most distinctive value. Extracting structured inventory data from source code using traditional tooling requires parsing, static analysis frameworks, and significant language-specific engineering for each programming language in the codebase. Writing an NLR that instructs AI to identify every external service call in a Python microservice and extract the target URL, the authentication method, and the data schema of the request body is a task that takes minutes to specify and seconds to execute — across any programming language, without a separate engineering effort per language.
What You End Up With
The pipeline described in this article — applied continuously to the artifacts the organization already produces, guided by Natural Language Rules that any domain expert can write and maintain — produces something that manual programs and traditional tooling have historically failed to deliver: a continuously maintained Enterprise Model that reflects the actual state of the enterprise.
Not a snapshot assembled over months and left to decay. Not a model that is complete for the systems the inventory team had time to document and silent on everything else. Not a program that requires a standing team of analysts performing the same work in perpetuity. An AI-assisted pipeline runs on a schedule, processes new and updated artifacts as they are produced, generates a manageable delta of proposed changes for human review and approval, and maintains the relationship layer that makes the model analytically useful.
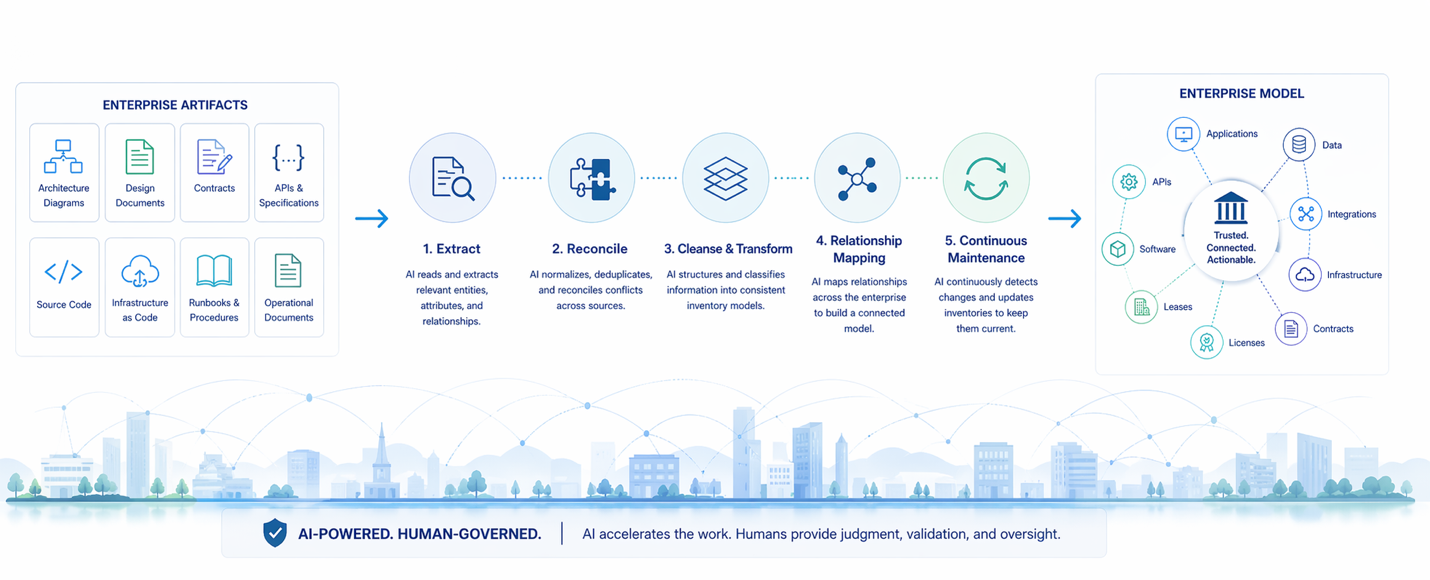
There is a significant side effect of this work that deserves to be named explicitly: the natural construction of the Enterprise Model — also known as the Enterprise Architecture Model (EAM). The Enterprise Model is something that most CTOs and Chief Architects aspire to build and rarely complete. It has historically eluded them not because the concept is wrong but because the complexity of creating and maintaining it manually, or through traditional tooling, has been prohibitive. The inventory management pipeline described here does not treat the Enterprise Model as a separate initiative requiring its own program, budget, and team. It builds the Enterprise Model as a byproduct — because a complete set of governed, relationship-rich, continuously maintained inventories is the Enterprise Model, in both structure and substance. Organizations that pursue this pipeline for the practical management benefits it delivers will find, as a natural consequence, that they have also produced the comprehensive, current, and queryable Enterprise Architecture Model that their architecture programs have long sought but rarely achieved.
The result is the foundation described in the companion article: an enterprise that knows what it has, maintains that knowledge continuously, enters every negotiation and audit from a position of documented fact, and can answer the questions that matter most to executive leadership without scrambling to assemble data that should already exist.
Closing Thought
The pipeline is not the destination. The destination is an enterprise that is no longer reactive — no longer assembling inventory data under pressure, no longer surrendering leverage because it does not know its own position, and no longer making strategic decisions from a foundation of approximation and assumption.
AI makes that destination achievable. Not through a technology project that requires months of development and a dedicated engineering team, but through Natural Language Rules that subject matter experts can write today, applied to artifacts the organization already has. The work is not in building the tooling. The work is in deciding what you want to know about your enterprise — and then telling AI how to find it.
Published by Guerino Enterprises, LLC – Copyright Guerino Enterprises & Frank Guerino