Data Integrations as Super-Tuples: Compound Relationships That Wire the Enterprise Model Together
In most graph models of the enterprise, relationships are predicates - static assertions that one node is connected to another through some descriptive label. Data Integrations are fundamentally different. They are Super-Tuples: compound relationship objects whose attributes are simultaneously descriptors of the integration itself and references to nodes, classification indexes, and operational facts that radiate outward across the entire Enterprise Model. More than that, Data Integrations describe flow - the directed, operational movement of data between nodes - giving them a temporal and behavioral dimension that no other relationship type carries. They are not the adjectives of the Enterprise Model. They are its verbs.

Author: Frank Guerino
A Quick Recap: Relationships as First-Class Objects
A prior article in this series - “Understanding Reified Relationships, N-Tuples, and How They Give Life to Data” - established that relationships in an enterprise graph do not have to be simple binary connections. Relationships can be reified: lifted from the status of anonymous edges into first-class objects with their own attributes, their own identities, and their own analytical value. A reified relationship is a node that represents an edge, with attributes that describe the nature of the connection in as much precision as the model requires.
This article goes further. It examines one specific class of reified relationship - the Data Integration - and shows that it is not simply a richer edge. It is something categorically more powerful: a compound object whose attributes are themselves relationships, pointing simultaneously to specific asset nodes, to classification index nodes that span entire inventory domains, and to operational facts about behavior over time. We call this a Super-Tuple. And we argue that Data Integrations, by virtue of being Super-Tuples that describe flow, occupy a unique and foundational position in the Enterprise Model that no other relationship type shares.
Defining the Super-Tuple Relationship
A Super-Tuple Relationship (STR or ST) is a compound reified relationship object involving three or more nodes, in which the relationship’s attributes function as node references rather than mere descriptors. The minimum structure is: a source node, a target node, and at least one additional node referenced by an attribute of the relationship itself. In practice, Super-Tuples involve many more nodes simultaneously - asset nodes, classification index nodes, and operational fact nodes across multiple inventory domains. The Super-Tuple is the most analytically generative relationship type in an enterprise graph precisely because each attribute it carries extends the relationship’s reach into a different domain of the model.
Where a predicate connects, a Super-Tuple radiates. It helps answer many questions while powering many insights.
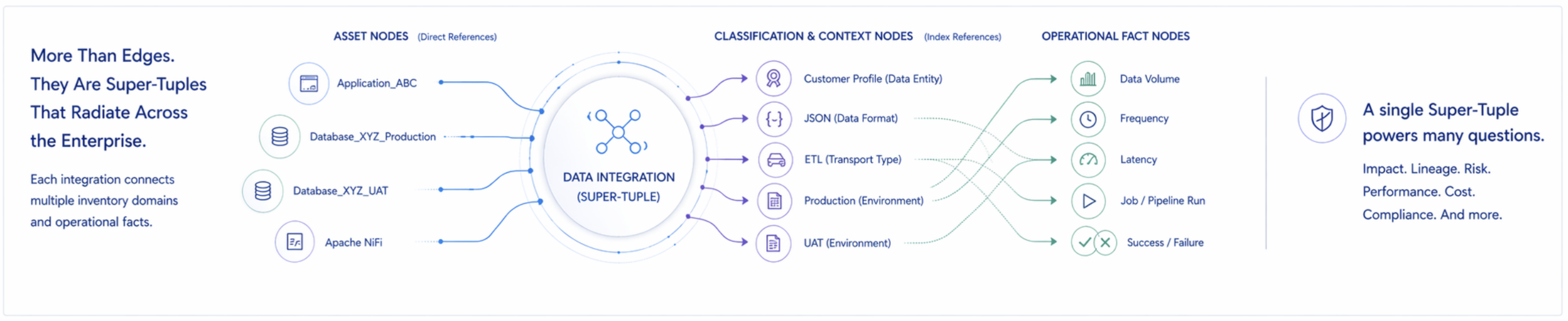
Two Concrete Examples Bound Together for a Super Example
Before developing the theory, ground it in specifics. Here are two Data Integration records drawn from a realistic enterprise context. Read through each one carefully - we will return to these examples repeatedly throughout the article, examining what each attribute actually does in the graph.
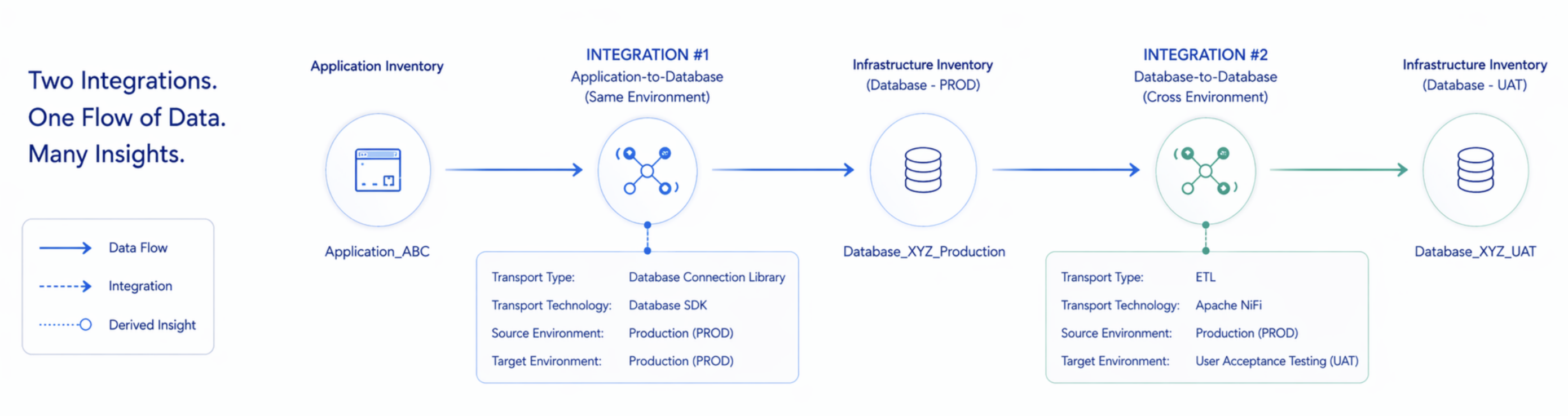
The above diagram highlights two independent and different Data Integrations that we’ll use as examples of Super-Tuple Relationships (a.k.a. Super-Tuples). These two Data Integrations each stand alone as 11-Tuple Data Integration Relationships and are also intentionally chained together to show the flow of a single data record through each Data Integration via a common connecting node identified as “Database_XYZ_Production” that is a Production environment database.
The details of these two Data Integration Super-Tuple Relationships are as follows…
Data Integration 1 (a.k.a. Example 1): Application-to-Database within same Environment via Database Connection Library
Integration Type = “Application-to-Database”
Source Environment = “Production (PROD)”
Source Component Type = “Application”
Source Component Identifier = “Application_ABC”
Data or Information Payload Description = “Customer Profile”
Data or Information Format = “JSON”
Transport Type = “Database Connection Library”
Transport Technology = “Database SDK”
Target Component “Type = Database”
Target Environment = “Production (PROD)”
Target Component Identifier = “Database_XYZ_Production”
Data Integration 2 (a.k.a. Example 2): Database-to-Database across different Environments via ETL
Integration Type = “Database-to-Database”
Source Environment = “Production (PROD) "
Source Component Type = “Database”
Source Component Identifier = “Database_XYZ_Production”
Data or Information Payload Description = “Customer Profile”
Data or Information Format = “JSON”
Transport Type = “Extract, Transform, & Load (ETL) "
Transport Technology = “Apache NiFi”
Target Component Type = “Database”
Target Environment = “User Acceptance Testing (UAT) "
Target Component Identifier = “Database_XYZ_UAT”
Each Data Integration is an example of a reified complex relationships, where we have environment nodes, source nodes, target nodes, data nodes, transport nodes, and more. Neither uses a clearly identifiable Descriptive Predicate, as we find in many 3-tuple relationships - in this case such descriptive predicates need to be implied or inferred by combining payload and transport tuples. And together, these two records describe a complex chain of constructs and the movement of data through them:
-
Application_ABC writes Customer Profile data to Database_XYZ_Production using a transport type that is a Database Connection Library.
-
A separate ETL process then extracts that same Customer Profile data from the production database and loads it into Database_XYZ_UAT, the User Acceptance Testing environment.
The example highlights: Two integration records; One data flow chain; Multiple inventory domains implicated (e.g., Applications, Databases, Data Integrations, Transport Types, etc.); And a data governance fact - Production data crossing an environment boundary into UAT. This is the Super-Tuple in action. But to better understand its rich value for a data graph that is the Enterprise Model, we need to dive in and examine its attributes individually.
Dimension 1: Direct Node References - Explicit Edges to Specific Assets
The first thing a Data Integration record does is create or validate explicit edges between specific named nodes in other inventory domains. Look at the direct references in our two examples:
In Example 1, the Source Component Identifier “Application_ABC” is not just a label - it is a pointer to a specific node in the Application Inventory. The Target Component Identifier “Database_XYZ_Production” is a pointer to a specific node in the Infrastructure Inventory. The Transport Technology “Database SDK” is a pointer to a node in the Software or Technology Inventory. The Data Payload “Customer Profile” is a pointer to a node in the Data & Information Inventory.
In Example 2, the Source Component Identifier “Database_XYZ_Production” is the same node that appeared as the target in Example 1 - creating a chain relationship across two integration records. The Transport Technology “Apache NiFi” points to a different technology node. And the Target Component Identifier “Database_XYZ_UAT” points to a node in the Infrastructure Inventory that represents the UAT environment instance of the same database.
What the direct references accomplish: A single integration record in Example 1 simultaneously creates four validated cross-domain relationships: Application_ABC → is connected to → Database_XYZ_Production; Application_ABC → uses → Database SDK; Application_ABC → moves → Customer Profile data; Customer Profile data → resides in → Database_XYZ_Production. None of these relationships are stored separately. They emerge from a single record’s attribute references. This is what makes the integration record a nexus - it generates relational surface area across the Enterprise Model far exceeding the storage cost of the record itself.
Dimension 2: Classification Nodes - Type Indexes That Imply Relationships Across the Graph
The second thing a Data Integration record does is more subtle and more powerful. Several of its attributes are not references to specific named nodes - they are references to classification nodes: nodes in the graph that act as type-level indexes, implying relationships to every node of that type across the entire model.
In most graph models, classification is treated as metadata - a property on a node, not a node in its own right. The insight here is that classifications should be nodes, with implied edges rather than explicitly stored ones. A node of type “Application” does not need an explicit edge drawn to the “Application” classification node. The edge is implied by the type assignment. Query the “Application” classification node and you traverse instantly to every application in the model, without those edges ever being individually stored.
Now look at what the classification attributes in our examples actually do:
Source Component Type = Application (Example 1). This references the “Application” classification node, which implicitly indexes every application in the Enterprise Model. The moment this attribute is populated, the integration record acquires an implied relationship to the entire application domain - specifically, it establishes Application_ABC as a member of the Application type, making it reachable through type-level traversal.
Target Component Type = Database (both examples). This references the “Database” classification node. Both Database_XYZ_Production and Database_XYZ_UAT are implicitly members of this type. Query “which databases are involved in integrations that carry Customer Profile data” and the classification node routes the traversal correctly without requiring explicit per-instance edges.
Integration Type = Application-to-Database (Example 1). This references the “Application-to-Database” integration pattern classification node. That node implicitly indexes every integration in the model that moves data from an application to a database. Query it and you retrieve every such integration - across all environments, all transport types, all payloads - in a single traversal step. This is how pattern-level analysis becomes tractable at enterprise scale.
Integration Type = Database-to-Database (Example 2). Similarly, this references the “Database-to-Database” classification node. Every peer database synchronization, replication job, and ETL pipeline in the enterprise is reachable from this node. Query it filtered by Source Environment = Production and Target Environment ≠ Production, and you immediately surface every cross-environment database integration - the exact data governance concern that Example 2 represents.
Source Environment = Production, Target Environment = UAT (Example 2). Environment names are not just labels either. They reference classification nodes for deployment environments. “Production” is a node that indexes every asset, integration, and process that operates in the production environment. “UAT” is a node that indexes its equivalent. The combination of Source Environment ≠ Target Environment is a detectable graph pattern - a cross-environment flow - that has immediate data governance implications without requiring a separate governance rule to be explicitly coded.
Data or Information Format = JSON (both examples). JSON is a format classification node. Every integration that carries JSON-formatted payloads is implicitly indexed here. This enables format-level governance queries: which integrations carry unstructured or schema-less payloads that may require additional validation controls?
A note on the power of classification nodes: The Integration Type attribute alone transforms what the integration record can answer. Example 1’s “Application-to-Database” classification means that querying for all Application-to-Database integrations in the enterprise returns this record alongside every other integration of that pattern - without any explicit edges between the records themselves. The classification node is the index. The attribute reference is the index key. The traversal is the query. This is how enterprise-scale analysis becomes feasible without storing every possible relationship explicitly.
Dimension 3: Derived Cross-Domain Relationships - What Emerges From Combining Dimensions 1 and 2
The most analytically powerful surface area of the Super-Tuple is not what it explicitly states - it is what it implies through the combination of its direct asset references and classification node references. These derived relationships are not stored anywhere. They emerge from traversal across the two dimensions simultaneously.
Consider what can be derived from our two examples together:
-
Application_ABC participates in Application-to-Database integrations. This is derivable by combining the Source Component Identifier (Dimension 1) with the Integration Type classification (Dimension 2). It was never stated explicitly anywhere.
-
Database_XYZ_Production is both a target in a same-environment application integration and a source in a cross-environment ETL pipeline. This dual role is only visible when the two integration records are read together through their shared node reference. It was never stated explicitly in either record.
-
Customer Profile data flows from Production to UAT. This is a data governance fact of significant consequence - Production data crossing an environment boundary raises questions about masking, anonymization, and regulatory compliance. It is derivable by combining the Data Payload reference (Dimension 1) across both examples with the Source Environment and Target Environment classification references (Dimension 2). It does not appear in any other inventory domain.
-
Apache NiFi is the technology used for cross-environment database synchronization in this estate. This is derivable by combining the Transport Technology reference (Dimension 1) with the Integration Type and Environment classification references (Dimension 2). An organization seeking to understand its ETL technology landscape and its cross-environment data movement landscape simultaneously can answer both questions from the same two records.
-
Database_XYZ_Production sits at a graph junction: it is a downstream consumer of Application_ABC and an upstream producer for Database_XYZ_UAT. Its position in the flow chain - a mid-stream node - is only visible when the derived relationship is computed across both records.
From the examples: Notice that the Customer Profile data governance finding - Production data flowing to UAT - does not appear in the Application Inventory, the Infrastructure Inventory, the Data Inventory, or the Contract Inventory. It is only visible in the Integration Inventory, specifically in the cross-example derived relationship. This is why the Integration Inventory is not merely one domain among many. It is the domain that makes certain governance facts visible that are invisible everywhere else.
The Ontological Difference: Predicates vs. Processes
We have now described what a Data Integration record carries structurally. But there is a deeper distinction that separates Data Integrations from every other relationship type in the Enterprise Model - a distinction that is not about the number of attributes or the complexity of the references. It is ontological: a difference in the kind of thing a Data Integration is.
Most relationships in an enterprise graph are existential predicates. They assert a fact about the state of the model that is either true or false at any given moment. “Application_ABC supports the Customer Onboarding capability.” “Database_XYZ_Production belongs to the Production environment.” “Contract_123 governs the relationship with Vendor_ABC.” These predicates are timeless in a specific sense: they describe what something is or has, not what it does. The relationship either holds or it does not. Remove the edge and the nodes are unchanged. Update the edge and the model is more accurate. But nothing operational changes in the real world.
A Data Integration relationship is categorically different. It is not a predicate. It is a process description. It describes something that executes repeatedly, carries a payload with properties, and has an operational state that changes over time. Remove the integration and something stops happening in the real world - right now, immediately, with operational consequences. The Customer Profile data that was arriving at Database_XYZ_Production every few hundred milliseconds stops arriving. Downstream systems that depended on that data begin working with stale information or fail outright. The UAT environment that was being synchronized from Production via Apache NiFi stops receiving updates. Testers working in UAT begin working against a snapshot rather than a current replica.
This is the ontological distinction: static relationships are adjectives. They describe what a node is. Data Integrations are verbs. They describe what the enterprise does, continuously, across time.
The adjective vs. verb distinction in practice: An incorrect static relationship is an accuracy problem. It may lead to a wrong answer in a query or a misleading entry in a report. A broken Data Integration is an operational failure happening right now. It is not a data quality issue - it is a production incident. This difference in consequence is a direct reflection of the ontological difference between predicates and processes. It is also why the Integration Inventory is the most operationally urgent inventory domain in the Enterprise Model. Errors in other inventories degrade analytical quality. Errors or omissions in the Integration Inventory can mean that a production incident goes undetected, a data governance violation goes unreported, or an impact analysis fails to identify a critical downstream dependency.
The Three Things a Data Integration Carries That Make it Different Than Other Relationships
The ontological distinction between predicates and processes maps onto three distinct information dimensions that Data Integrations carry simultaneously, and that no other relationship type in the Enterprise Model carries:
Structural Information
Which two nodes are connected, through what mechanism, and in what direction. This is the static edge that every relationship type carries. It tells you that Application_ABC is connected to Database_XYZ_Production via a Database Connection Library. Every other relationship type stops here. The integration record begins here.
Payload Information
What flows between the nodes: the data entity being transported, its format, its schema, its classification, and its regulatory status. In Example 1, Customer Profile data flows in JSON format. In Example 2, the same Customer Profile data flows via ETL. This is the Super-Tuple nexus dimension - the payload attributes that create cross-domain references to the Data & Information Inventory, the data format classification nodes, and the regulatory obligation nodes that govern the handling of this specific data type.
No other relationship type carries payload information, because no other relationship type involves the movement of a data entity. A static predicate connects nodes. A Data Integration moves something between them, and the nature of what it moves determines its governance implications, its regulatory exposure, and its operational criticality. Customer Profile data flowing from Production to UAT is not the same as configuration data flowing between the same two environments. The payload is what makes the distinction.
Operational Information
How and when the flow occurs: trigger type (event-driven, scheduled, on-demand), frequency, volume, SLA commitments, error handling pattern, retry behavior, latency tolerance, and monitoring status. In Example 1, a Database SDK implies a synchronous, low-latency connection - likely called directly within application code, possibly on every transaction. In Example 2, Apache NiFi implies a scheduled or event-triggered ETL process, likely running periodically rather than continuously, with buffering and retry behavior appropriate for a bulk transfer workload.
These operational properties only make sense for something that runs. They have no meaning for a static predicate. “Application_ABC supports Customer Onboarding” has no frequency, no SLA, no retry behavior. But “Application_ABC writes Customer Profile data to Database_XYZ_Production via Database SDK” does. It runs at some frequency. It has a latency profile. It fails in specific ways. It has a recovery pattern. These properties are what make the integration record a living artifact in the operational model, not merely an entry in a catalog.
Why operational information matters to executive leadership:
-
An executive who asks “where do we move data from lower environments into our production environment and risk being flagged in audits?” needs compliance information (i.e., which integrations violate policy).
-
An executive who asks “if we upgrade Database_XYZ_Production, what is affected?” needs structural information: which integrations touch this node.
-
An executive who asks “how urgent is it to fix this integration if it breaks?” needs payload information (i.e., what data is being moved and what are its downstream dependencies).
-
An executive who asks “how would we know if this integration broke?” needs operational information (i.e., what monitoring exists, what the SLA is, and what the failure mode looks like).
All four questions are answerable from the integration record. None are answerable from a static predicate whose only function is to describe how two nodes are bound together.
Flow, Direction, and Dependency Asymmetry
There is one more dimension of the Data Integration that requires explicit treatment, because it is the property most directly responsible for making impact analysis and root cause analysis reliable: flow direction.
Think of a Data Integration the way you would think of current moving through a wire or water moving through a pipe. The wire does not simply connect two terminals - it carries current in a specific direction, at a specific voltage and amperage, under specific load conditions. The pipe does not simply connect two reservoirs - it carries fluid in a specific direction, at a specific pressure and flow rate, subject to specific capacity constraints. The structural connection is the same regardless of direction. But the operational reality is entirely determined by direction.
A static relationship edge in a graph is, in a meaningful sense, direction-agnostic. “Application_ABC depends on Database_XYZ_Production” could be read as “Application_ABC calls Database_XYZ_Production” or as “Database_XYZ_Production serves Application_ABC” - both are accurate, but neither tells you with operational precision what breaks first when something fails.
A Data Integration is explicitly directional. Application_ABC is the producer. Database_XYZ_Production is the consumer. This asymmetry is not a detail - it is the operationally critical fact. Consider what it means in practice:
-
If Application_ABC stops writing - because it crashes, because it is taken offline for maintenance, or because a code change breaks the write path - Database_XYZ_Production stops receiving Customer Profile updates. The data in the database becomes stale. Systems that read from the database continue to function, but they operate on outdated information. The failure propagates downstream silently, through the data rather than through a visible error.
-
If Database_XYZ_Production becomes unavailable - because of a hardware failure, a network partition, or a maintenance window - Application_ABC may queue writes, block on the connection attempt, time out, or fail hard, depending on the error handling model specified in the integration. The failure propagates upstream, back to the producer, potentially surfacing as an application error visible to end users.
-
If the ETL process in Example 2 stops running - because Apache NiFi is unavailable, because the schedule is misconfigured, or because the production database is unreachable - Database_XYZ_UAT stops receiving Customer Profile updates. Testers in the UAT environment begin working against a snapshot rather than a current replica. Defects that depend on current production data become undetectable in UAT.
In each case, the direction of flow determines the failure propagation path. Knowing the structural connection tells you that two nodes are related. Knowing the flow direction tells you which node is the upstream source of truth and which is the downstream consumer, which failure modes propagate forward through the data and which propagate backward through the connection, and which teams are affected first when the integration degrades.
From Example 2 - a flow chain with governance implications: Because Example 2’s flow is directional - Production to UAT, not bidirectional - the data governance and compliance concern is specific: Production data is flowing into a non-Production environment. The reverse (UAT data flowing into Production) would be a different and potentially more severe concern. The direction is what makes the governance question precise. A bidirectional or direction-agnostic edge would obscure this distinction entirely.
This is why flow direction is not a decorative attribute in the integration record - it is a load-bearing analytical property. Impact analysis without flow direction tells you which nodes are connected. Impact analysis with flow direction tells you which nodes are upstream producers, which are downstream consumers, and therefore which direction failures will cascade. Root cause analysis without flow direction traces a path through a symmetric graph. Root cause analysis with flow direction follows the causal chain: the failure originated here, propagated in this direction, and manifested there.
Why This Makes The Integration Inventory One Of The Most Operationally Critical Domains in the Enterprise Model
Every inventory domain in the Enterprise Model has value. But not every domain has the same relationship to operational reality. Most inventory domains describe the world as it is: applications exist, contracts are in force, licenses are held, capabilities are supported. These are facts about a state. Errors in these inventories are accuracy problems - they degrade the quality of analysis and reporting, but they do not immediately cause anything to break.
The Integration Inventory describes the world as it operates. It does not just say that Application_ABC is connected to Database_XYZ_Production. It says that Customer Profile data is flowing from Application_ABC to Database_XYZ_Production right now, via a Database SDK, and that this flow is part of a chain that continues to Database_XYZ_UAT via Apache NiFi. An error or omission in the Integration Inventory is not just an accuracy problem. It is a blind spot in the operational model of the enterprise. It means that an impact analysis will miss a dependency. It means that a root cause analysis will fail to trace a failure path. It means that a data governance audit will miss a cross-environment data flow.
The Super-Tuple nature of the integration record amplifies this operational criticality. Because every integration record simultaneously carries structural, payload, and operational information, and simultaneously references specific asset nodes and classification index nodes across multiple inventory domains, a single missing or incorrect integration record creates multiple blind spots simultaneously: a missing edge in the graph, a missing payload reference in the data governance model, a missing entry in the pattern classification index, and a missing operational fact in the impact analysis model.
This compounding effect is why the Integration Inventory must be treated as a first-order management asset, not a secondary documentation artifact. Organizations that maintain it accurately and completely can answer the questions that matter most to operational leadership - what is flowing where, what depends on what, what breaks if this changes - with speed and confidence. Organizations that do not answer those questions slowly, incompletely, and at significant risk of missing something consequential in the answer.
Additionally, I will add the insight that multiple other inventories can be reverse engineered from the Data Integration inventory and, simultaneously, it can be used to reconcile those other inventories for quality.
Closing Thought
Most enterprises build graph models of their technology landscape that describe what they have. Nodes for applications, databases, capabilities, vendors, contracts. Edges for the relationships between them. This is necessary and valuable - but it is not sufficient.
What makes an Enterprise Model genuinely useful for operational management is not just the nodes and the static edges that act as adjectives for how nodes are bound together. It is also the verbs: the Data Integrations that describe what the enterprise does, continuously, across time. And what makes Data Integrations uniquely powerful as model elements is that they are Super-Tuples - compound objects whose attributes simultaneously reference specific assets, index entire asset classes through classification nodes, and describe the operational behavior of a living flow process.
The two examples in this article - a single application writing Customer Profile data to a production database, and an ETL process synchronizing that data to a UAT environment - are individually simple. But together, in a properly maintained Enterprise Model, they surface a data flow chain, a cross-environment data governance and compliance concern, a technology dependency map, a failure propagation path, and a set of impact analysis inputs that no other pair of records in any other inventory domain could surface alone.
That is the Super-Tuple. That is the verb. And that is why the Data Integration Inventory, maintained with the precision and completeness it deserves, is the connective tissue that transforms a collection of inventory domains into an Enterprise Model capable of answering the questions that matter most.
Where a predicate simply connects, a Super-Tuple radiates new and far more powerful information.
Published by Guerino Enterprises, LLC – Copyright Guerino Enterprises & Frank Guerino