Make Architecture More Valuable: Have Enterprise Architecture Own the CMDB
The Configuration Management Database (CMDB) and the Enterprise Model are, at their core, attempts to describe the same thing: the assets that compose the enterprise, their attributes, and the relationships between them. Yet in most organizations they are owned by different teams, maintained at different points in the asset lifecycle, and allowed to diverge in ways that damage both. The CMDB is given to operations, where it stagnates. The Enterprise Model is owned by Architecture, where it thrives — but its value is limited by the fact that the operational processes that most need it are drawing from a CMDB that does not reflect it. This article argues that Enterprise Architecture should take ownership of the CMDB, and explains what changes when it does.
Author: Frank Guerino
The CMDB’s Unfulfilled Promise
The Configuration Management Database was conceived as the authoritative, organization-wide inventory of the technology estate: a single source of truth for every asset the organization owns or operates, every relationship between those assets, and every dependency that matters when something changes or breaks. The promise was compelling. A well-maintained CMDB would make impact analysis reliable, change management accurate, incident response faster, and compliance audits tractable. It would be the operational nervous system of the enterprise — the model that every team draws from when they need to understand what exists, what connects to what, and what the consequences of any significant action will be.
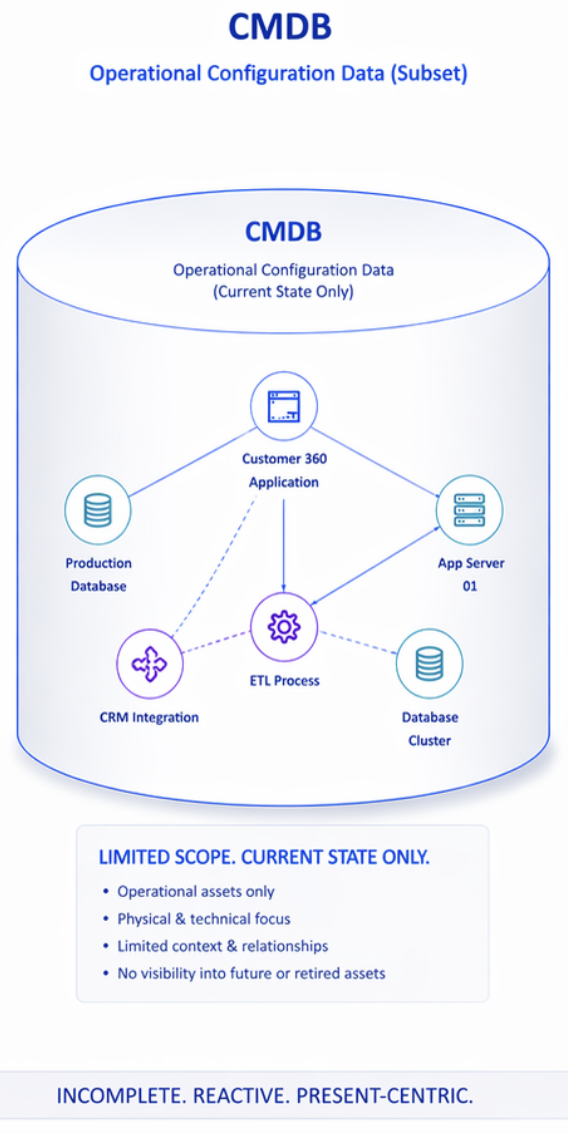
In practice, most CMDBs fail to deliver on this promise. They are incomplete. They are chronically out of date. They are trusted by almost nobody who has spent any time examining their contents critically. Teams that depend on accurate asset and relationship data have learned, through repeated experience, that the CMDB cannot be relied upon — and they have built workarounds: spreadsheets, tribal knowledge, direct interviews with application owners, and manual investigation that should not be necessary in any organization that has invested in a CMDB at all.
This failure is consistent across industries, organizational sizes, and CMDB technology platforms. It has been observed at Merrill Lynch and across many other organizations spanning financial services, life sciences, pharmaceuticals, healthcare, defense, and manufacturing. The specific details differ — the platform, the scope, the severity of the gap — but the pattern is the same everywhere: a CMDB that was supposed to be the authoritative source of truth for the technology estate, and is not. The cause is not the technology. It is the ownership model.
Two Artifacts, One Intent: The Enterprise Model and the CMDB as Enterprise Data Graphs
To understand why the ownership problem matters so much, it helps to be precise about what the Enterprise Model and the CMDB each are — not just what they contain, but what kind of artifact they are and what makes them valuable. When you examine them clearly, they are the same kind of thing: enterprise data graphs. And the shared nature of what they are is the reason their divergence is so damaging.
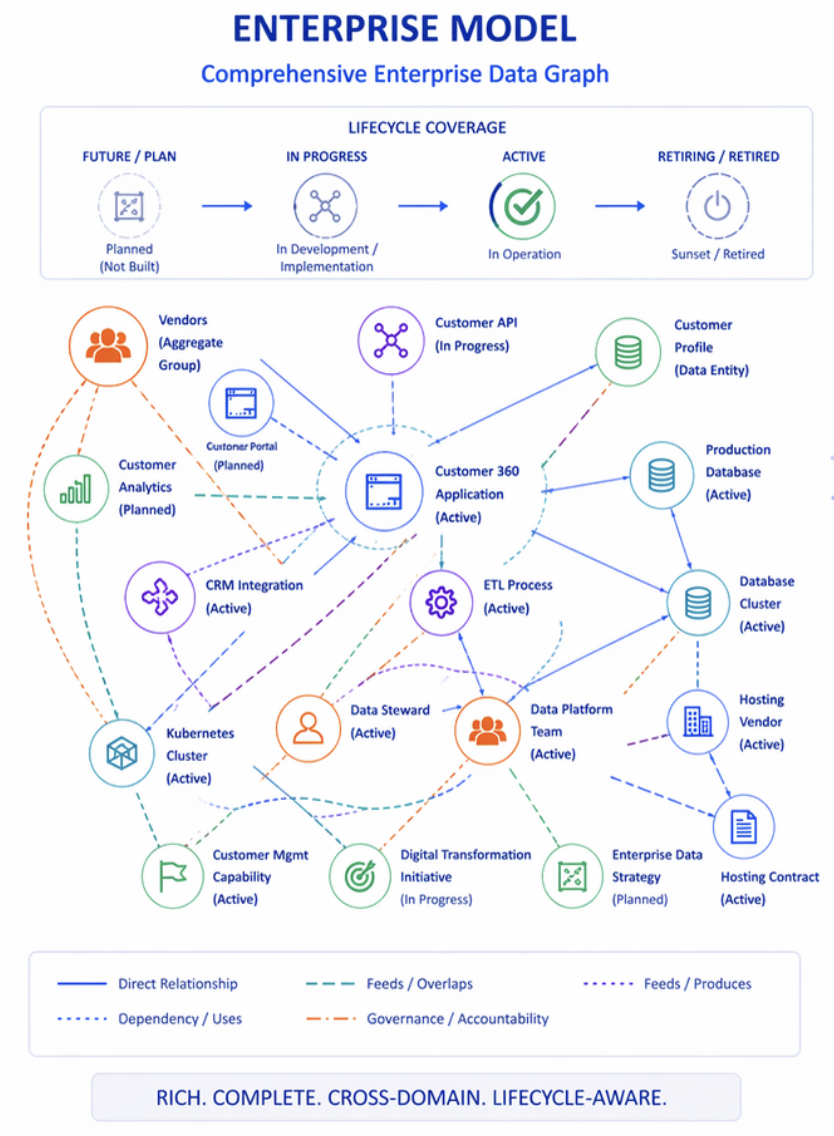
The Enterprise Model is an Architecture-owned, relationship-rich representation of the enterprise’s technology landscape and the assets that compose it. It spans the full asset lifecycle — from future-state assets that are planned but not yet built, through active assets in steady-state operation, to assets approaching retirement. It is organized as a graph in which every node is an asset — an application, a business capability, a data integration, an infrastructure component, a vendor, a contract, a person — and every edge is a typed, attributed relationship between assets. Its value derives not from any individual record but from the ability to traverse relationships across domains: to follow a chain from a business capability to the applications that implement it, to the integrations those applications depend on, to the infrastructure those integrations run on, to the contracts that govern the vendors who supply that infrastructure. The Enterprise Model is used for strategic planning, investment decisions, impact analysis, cost management, regulatory compliance, and the full range of executive decision-making described in the companion article on enterprise inventories.
The CMDB is an operations-owned, relationship-rich catalog of configuration items (CIs) and their dependencies within the technology estate. It is intended to reflect the current operational state of every managed asset: which servers exist, which software is installed on them, which applications are running, which services depend on which infrastructure components, and how changes to any one component will ripple through the systems that depend on it. It is organized, like the Enterprise Model, as a graph — CI nodes connected by typed relationship edges. Its value derives from the same traversal capability: follow the dependency chain from an affected CI outward to understand impact, inward to trace root cause. The CMDB is used for change management approvals, incident response, compliance audits, capacity planning, and ITSM process execution.
The shared intent is explicit once stated: both artifacts are enterprise data graphs. Both build a model of enterprise assets as typed nodes. Both capture relationships between those assets as typed edges. Both derive their value from the completeness of those nodes, the accuracy of those edges, and the ability to traverse the resulting graph to answer questions that no flat list or simple inventory could answer. Both are attempting to model the same underlying reality — the enterprise’s technology estate, its assets, and their interconnections.
The differences are real but secondary. The Enterprise Model emphasizes strategic and architectural scope: it covers future state, logical constructs like capabilities and processes, and the cross-domain relationships that span organizational boundaries. The CMDB emphasizes operational scope: it covers current state, physical assets and configurations, and the dependency relationships that matter for ITSM workflows. These emphases are complementary, not contradictory. An ideal enterprise data graph would encompass both — and in an organization where the two are properly integrated, it does.
The reason this shared nature matters is that errors and gaps in a graph model are fundamentally more damaging than errors and gaps in a flat list. If an application is missing from a spreadsheet inventory, one record is wrong. If an application is missing from a graph model, every relationship that should connect to that application is also missing or broken — every traversal that would have passed through that node returns an incomplete result, and every analytical conclusion based on those traversals is potentially wrong. A graph with missing nodes and incorrect edges does not merely produce inaccurate answers. It produces confidently inaccurate answers, because the traversal completes and returns a result — just not the right one. This is why the divergence between the Enterprise Model and the CMDB, allowed to compound over time without synchronization, is not a minor data quality problem. It is a structural failure in the enterprise’s ability to reason about itself.
What the CMDB Is Supposed to Contain
Before diagnosing why CMDBs fail, it is worth being explicit about what a well-maintained CMDB is supposed to contain. The scope is broader than many organizations realize, and understanding it is essential to understanding why the ownership model matters so much.
A complete CMDB should catalog every significant configuration item (CI) in the technology estate and the relationships between them. The CI types that matter most include:
-
Business capabilities and functions — the logical capabilities the organization must perform, independent of the technology that implements them
-
Applications — every software application the organization owns, licenses, or operates, whether commercial, SaaS, or custom-built
-
Databases and data stores — every database, object store, file system, and data platform the organization manages
-
Computing devices — servers, workstations, laptops, mobile devices, mainframes, and virtual machines
-
Software technologies — operating systems, middleware, frameworks, libraries, and runtime platforms
-
Data integrations — every integration that moves data or triggers processes between systems
-
Network and infrastructure components — routers, switches, firewalls, load balancers, and connectivity assets
-
Cloud resources — virtual machines, containers, managed services, and cloud platform subscriptions
Equally important are the relationships between these CI types: which applications run on which infrastructure, which integrations connect which systems, which capabilities are implemented by which applications, which software technologies are deployed on which devices. These relationships are what make the CMDB analytically useful rather than merely a catalog. Without them, the CMDB is a list. With them, it is a model.
This scope is, without exception, the same scope that Enterprise Architecture is responsible for when it builds and maintains the Enterprise Model. The overlap is not incidental — it is complete. Both artifacts are attempting to describe the same reality. The question is only who does it better, and why.
Why the CMDB Fails as a Data Graph: Architectural Limitations
The ownership and skills problems described in this article are real and significant. But there is a deeper layer of failure that is less often named: the CMDB does not just fail because of who maintains it. It fails because of how it is built. Most CMDB implementations are architecturally incapable of functioning as true enterprise data graphs, and the specific limitations that prevent them from doing so are structural — they cannot be fixed by assigning better people or improving governance processes. They require a fundamentally different data model.
The Absence of Descriptive Predicates
A true data graph represents relationships as first-class objects with their own typed, attributed predicates. “Application_ABC supports Customer Onboarding” is not merely a connection between two nodes — it is a typed relationship with a predicate (“supports”) that carries semantic meaning, and potentially additional attributes (since when, at what maturity level, as primary or secondary implementer). The predicate is what makes the relationship analytically useful: it tells you not just that two nodes are connected but what the nature of the connection is and what it means.
Most CMDB platforms do not support descriptive predicates in any meaningful sense. Relationships between CIs are represented as simple, untyped or minimally typed connections — “connected to,” “depends on,” “installed on” — with no ability to define a rich vocabulary of relationship types, no support for relationship-level attributes, and no mechanism for expressing the semantic distinctions that make graph traversal analytically powerful. The result is a flat, semantically impoverished connection model that can tell you two nodes are related but cannot tell you how, in what direction the dependency runs, with what strength or significance, or under what conditions the relationship applies.
This absence of descriptive predicates is not a minor limitation. It is the difference between a graph that can answer “what are the causal dependencies in this failure chain” and one that can only answer “what is connected to what.” The Enterprise Model, built on a proper graph data model or a well-governed relational model with explicit relationship typing, supports the full vocabulary of typed, attributed relationships that make the model analytically useful. The CMDB, constrained by its connection model, supports only a shadow of that capability.
The Fixed Schema Problem
The deeper architectural constraint is the fixed schema model that most CMDB platforms impose. Traditional CMDBs were built on relational database foundations with a predetermined set of CI classes — server, application, database, network device, software — each with a fixed set of attributes defined at implementation time. This schema reflects the asset types that existed and were well understood at the time the platform was designed. It does not reflect the asset types that matter to any specific enterprise, the new asset categories that have emerged as technology has evolved, or the relationship types that are needed to model the specific structure of a given organization’s technology estate.
Defining a new CI class — a new node type — in most CMDB platforms is a time-consuming, technically demanding process that requires platform administration expertise, schema change management, and in many cases vendor involvement or professional services engagement. It is not something an architect can do in response to a new analytical need that emerges from a planning exercise. By the time the new CI class is defined, approved, and available, the need that motivated it has often been addressed through workarounds, or the architectural context has changed enough that the original definition is already partially obsolete.
Defining new relationship types is even more constrained. In many CMDB platforms, the set of available relationship types is effectively fixed at implementation time, and adding new relationship types — particularly relationship types with their own attributes, the descriptive predicates described above — is either technically impossible within the platform’s data model or so laborious that it is practically never done. The relationship vocabulary the CMDB can express is determined not by what the enterprise needs to model but by what the platform vendor anticipated when they designed the schema.
This fixed schema model creates two compounding problems. First, it means that asset types and relationship types that are critical for the Enterprise Model — capabilities, processes, data integrations, logical relationships between applications and the data they own, relationships between vendors and the systems they provide — either do not exist in the CMDB at all or are forced into ill-fitting CI classes that distort their meaning. Second, and more severely, once a CI class is populated with operational data, changing its schema becomes functionally impossible. The data that exists locks the schema in place. An organization that discovers, after loading thousands of application records, that the application CI class is missing a critical attribute has no clean path to adding it. The migration cost is prohibitive, the platform may not support it gracefully, and the operational processes that depend on the existing schema resist the change. The CMDB becomes frozen at the level of completeness it had when it was first populated.
The Consequence: A Graph in Name Only
The combined effect of these architectural limitations is that most CMDBs are data graphs in intent but relational tables in implementation. The semantic richness required for meaningful graph traversal — typed relationships with descriptive predicates, flexible node schemas that can evolve as the enterprise evolves, and the ability to define new asset categories and relationship types as analytical needs emerge — is largely absent. What exists instead is a fixed-schema relational model with a relationship table, dressed in graph terminology but incapable of delivering graph-level analytical value.
The Enterprise Model, whether implemented in a proper graph database, a well-designed relational schema with explicit relationship typing, or even a well-governed set of connected inventories, does not carry these constraints. New asset types can be added as new categories become relevant. New relationship types with full predicate vocabularies can be defined as analytical needs emerge. The schema evolves with the enterprise rather than constraining the enterprise to the schema it had when the model was first built. This architectural flexibility is not a minor advantage — it is the difference between a model that can grow in accuracy and analytical power over time and one that is frozen at its initial level of completeness.
Why the CMDB Ends Up With Operations — and Why That Fails
The conventional logic for giving the CMDB to operations is straightforward: operations teams are responsible for the day-to-day management of technology assets, so they should be responsible for keeping the inventory of those assets current. The logic is not unreasonable in principle. It fails in practice for structural reasons that no amount of process discipline or tooling investment can fully overcome.
The first structural failure is lifecycle position. Operations teams engage with assets at the tail end of the lifecycle — after design, after build, after deployment, after change management has approved the modification and the change has been implemented. By that point, the Enterprise Model maintained by Architecture already contains the asset, described in more detail, with its relationships already mapped, often weeks or months earlier. Operations is always behind. The CMDB, fed from operations, is always a lagging view of a reality that Architecture has already modeled more accurately upstream.
The second structural failure is scope. Operations teams manage what they can see from where they stand: the infrastructure they monitor, the applications they support, the incidents they respond to. Their visibility is real but bounded. They rarely have the cross-domain, cross-organizational scope required to maintain a CMDB as a comprehensive Enterprise Model. The relationship between a business capability and the application that implements it, or between an application and the data integration that feeds it, or between a software license and the deployment that consumes it — these are architectural relationships that operations teams are not typically positioned to establish or maintain.
The third structural failure is skills. Maintaining the logical layer of a CMDB — the capabilities, the applications, the integrations, and the relationships between them — requires enterprise modeling knowledge: the ability to define relationship types, manage taxonomies, reason about dependency chains, and maintain the consistency of a complex connected model as it evolves over time. This is not a criticism of operations professionals, who possess deep and valuable expertise in their own domain. It is an observation about what is required to maintain an enterprise-scale relational model. That expertise lives in Enterprise Architecture, not in operations.
The fourth structural failure is the handling of state. A CMDB needs to represent both current state and future state — assets that are planned but not yet deployed, assets that are in the process of being retired, and the target architecture toward which the organization is moving. Operations has no visibility into future state at all. Its view is restricted to what currently exists and is currently running. Architecture, by contrast, works with future state as a primary concern. The Enterprise Model routinely contains assets that do not yet exist in any operational system and relationship mappings that reflect the architecture the organization is building toward. A CMDB that only reflects what operations can observe is, by definition, always incomplete.
The Two-Layer Problem: Auto-Discovery Richness vs. Logical Layer Poverty
Most modern CMDB implementations include an auto-discovery capability: automated scanning tools that interrogate the network and infrastructure to identify and catalog physical assets — servers, devices, software installations, network components — and populate the CMDB with what they find. This capability works reasonably well for what it does. The physical, discoverable layer of the CMDB — servers, installed software versions, network topology, device inventory — is often well-populated and reasonably current, because auto-discovery tools run continuously and update records automatically.
The logical layer is a different story entirely. Auto-discovery cannot observe logical assets. It cannot see a business capability. It cannot identify a data integration that exists as application code rather than a network connection. It cannot map the relationship between an application and the business process it supports, or between a software license and the deployments that consume it, or between a database and the data entities it stores. These relationships are not discoverable by any automated tool. They must be known, and they must be manually created and maintained by people who understand the enterprise well enough to define them accurately.
In practice, this means the logical layer of the CMDB is almost universally impoverished. The relationships between logical assets — application-to-capability, application-to-data-integration, capability-to-process — are sparse, inaccurate, or absent. The relationships between logical and physical assets — application-to-server, application-to-database, service-to-infrastructure — are partially populated at best, riddled with gaps, and frequently wrong where they exist. The auto-discovery tools cannot create these relationships. The operations teams assigned to maintain them do not have the knowledge to do so reliably. And because nobody is accountable for the quality of the logical layer specifically, it is allowed to decay until it is functionally useless.
This two-layer problem is one of the most consistent findings across every organization where this issue has been examined. The physical layer is passable. The logical layer is, in the honest assessment of most practitioners who have examined it critically, essentially worthless for any analytical purpose that requires understanding how the enterprise actually works. Impact analysis that depends on the CMDB’s logical relationships produces incomplete and often misleading results. Change management that relies on it misses dependencies. Incident response that consults it for context is working with an incomplete picture of what is connected to what.
The Lifecycle Asymmetry: Architecture Is Upstream
The most important structural argument for Architecture owning the CMDB is the lifecycle asymmetry between the two functions. Architecture engages with assets at the earliest possible stage — during strategic planning, capability modeling, solution design, and technology roadmap development. The Enterprise Model reflects assets in multiple lifecycle states simultaneously: future-state assets that are planned but not yet built, assets under active development, assets recently deployed and being transitioned to steady-state operations, assets in maintenance mode, and assets approaching end-of-life and scheduled for retirement.
The CMDB, in most organizations, reflects only one of these lifecycle states: operational current state. Assets appear in the CMDB when operations discovers or registers them after deployment. They remain in the CMDB, often unchanged, until someone manually removes them. Future-state assets do not appear at all. Assets in retirement planning are not distinguished from fully active assets. The lifecycle context that makes asset data useful for planning and decision-making is entirely absent.
This asymmetry means that by the time an asset reaches the CMDB through the operational discovery process, Architecture has already been working with it for weeks, months, or in some cases years. The CMDB is a downstream consumer of reality that Architecture has already modeled upstream. Every asset in the CMDB could, in principle, have been populated from the Enterprise Model before the operational discovery tools ever found it — with more complete attribute data, more accurate relationship mappings, and richer context than any auto-discovery tool or junior operations resource could provide.
This upstream position is not just an advantage for data completeness. It is the fundamental reason why Architecture is the right owner of the CMDB. Ownership should follow knowledge. Architecture knows the enterprise earlier, more completely, and across a broader scope than any other function. The CMDB should reflect what Architecture knows — which means Architecture should control what goes into it.
The Functional Overlap Is Not a Coincidence
When you examine the CI types and relationship types that a well-maintained CMDB is designed to cover, and compare them to the inventory domains and relationship types that a well-maintained Enterprise Model covers, the overlap is not partial — it is near-total. Every major CI type in the CMDB has a direct counterpart in the Enterprise Model. Every relationship category the CMDB is supposed to maintain is a relationship category that Architecture maintains in the Enterprise Model as a matter of course.
This is not a coincidence. It reflects the fact that both artifacts are, at their core, attempts to model the same reality: the assets that compose the enterprise and the relationships between them. The CMDB emerged from the IT service management tradition, oriented toward operational support and change management. The Enterprise Model emerged from the enterprise architecture tradition, oriented toward strategic planning, design, and governance. Different origins, different vocabularies, different tooling — but the same underlying object of description.
The practical implication is that maintaining both independently is redundant by definition. Every asset that appears in the CMDB should also appear in the Enterprise Model, with more context. Every relationship in the CMDB should also exist in the Enterprise Model, with more precision. Every query that the CMDB is supposed to support — what depends on this asset, what will be affected by this change, what is the impact radius of this incident — the Enterprise Model can answer more completely, because it contains more of the information required to answer it.
The organizations that recognize this and act on it — by bringing the CMDB under Architecture’s ownership or establishing a tight synchronization between the two — eliminate the redundant effort of maintaining two models of the same reality and inherit all of the benefits of having a single, authoritative, Architecture-quality model that operational processes can draw from.
What Happens When They Are Allowed to Diverge
The cost of maintaining a CMDB and an Enterprise Model as separate, unsynchronized representations of the same reality is not theoretical. It shows up concretely, repeatedly, and in ways that are measurable. These consequences have been observed consistently across organizations of different sizes, industries, and technology landscapes.
Incident response is slower and less accurate. When an incident occurs, the first question is: what is affected? Answering that question requires an accurate map of the dependency relationships between the affected asset and everything that depends on it. If the CMDB’s dependency map is incomplete or wrong — which it almost always is when the logical layer has been allowed to decay — the impact assessment misses dependencies. Teams that should be notified are not. Systems that will be affected are not prepared. The blast radius is discovered through the incident rather than in advance of it, which is the most expensive way to discover it.
Change management approvals are based on incomplete impact assessments. Change advisory boards review proposed changes against the dependency map to assess risk. A CMDB that does not accurately reflect the logical relationships between assets produces impact assessments that miss critical dependencies. Changes that would have been staged, sequenced, or rejected proceed without adequate preparation. The resulting incidents are attributed to operational failure rather than to the asset model that should have predicted them.
Compliance audits surface discrepancies that damage credibility. Regulatory examinations frequently include requests for asset inventories, system inventories, and dependency maps. When the CMDB and the Enterprise Model produce different answers to the same question — which they will, if they have been allowed to diverge — the organization cannot present a coherent, authoritative response. The discrepancy becomes a finding. The investigation into the discrepancy consumes management time and organizational credibility. The root cause — two teams maintaining two models of the same reality with no synchronization — is rarely addressed in the remediation plan.
Architecture is called in to answer questions the CMDB should be answering. This is perhaps the most telling consequence. When an operational team needs to understand the dependencies around a system, the scope of a change, or the impact of an incident, and the CMDB cannot provide a reliable answer, they call Architecture. Architecture answers the question from the Enterprise Model. This happens so consistently in organizations where the two are not synchronized that it has become an informal norm: the CMDB is where you file the ticket, and Architecture is where you get the actual answer. This norm is costly, because it consumes Architecture’s time on operational support work, and it is dishonest, because it acknowledges the CMDB’s failure without addressing it.
The Right Answer: Architecture Takes Ownership
The case for Enterprise Architecture taking ownership of the CMDB is not primarily a political argument. It is a practical one, grounded in which team has the knowledge, the lifecycle position, the organizational scope, and the modeling skills to maintain a CMDB that is actually useful.
Architecture has all four. It knows the enterprise earlier and more completely than any other function. It models assets across the full lifecycle, from future state through retirement. It operates across organizational and domain boundaries that operations teams rarely cross. And it maintains, as a core competency, the enterprise modeling discipline that maintaining a useful CMDB requires. The question is not whether Architecture is capable of owning the CMDB. It is why Architecture has not already been given this responsibility everywhere.
Ownership means specific things in this context. It means Architecture defines the CMDB schema — the CI types, the attribute definitions, the relationship types, and the classification taxonomies that determine what the CMDB can describe and how it describes it. It means Architecture governs the quality of the logical layer — the application-to-capability relationships, the application-to-integration relationships, the logical-to-physical mappings that auto-discovery cannot provide and that operations teams cannot maintain reliably. It means Architecture is accountable for the accuracy and completeness of the CMDB as a whole, not just the portions that auto-discovery tools can populate automatically.
Ownership does not mean that Architecture does all of the data entry. The federated model described in the companion article on Enterprise Inventories applies here: operations teams continue to contribute the physical and operational layer data they are best positioned to maintain — patch levels, configuration states, availability records, incident histories. But the schema they contribute into, the relationships they create, and the model they are maintaining are defined and governed by Architecture. The CMDB becomes a governed, Architecture-quality model that operational processes can draw from with confidence, rather than an operations-maintained artifact that nobody fully trusts.
There is a resource optimization argument here as well, and it is one that finance and operations leadership can readily understand. When Architecture manages the Enterprise Model and operations manages the CMDB independently, the organization is paying for two teams to maintain two models of the same reality. The skills required to maintain the logical layer of the CMDB are the same skills Architecture already employs to maintain the Enterprise Model. Consolidating ownership eliminates duplicate effort, eliminates the synchronization gap, and optimizes the application of scarce enterprise modeling expertise. The savings in analyst time and the improvement in model quality both accrue from the same consolidation decision.
The Minimum Viable Alternative: Feed the CMDB From the Enterprise Model
Not every organization is positioned to transfer CMDB ownership to Architecture immediately. Organizational constraints, contractual obligations with managed service providers, ITSM platform governance structures, and entrenched operational workflows can make a clean ownership transfer difficult or slow. For organizations in this position, there is a minimum viable alternative that captures most of the benefit without requiring a full ownership change: establish an automated, governed synchronization from the Enterprise Model to the CMDB.
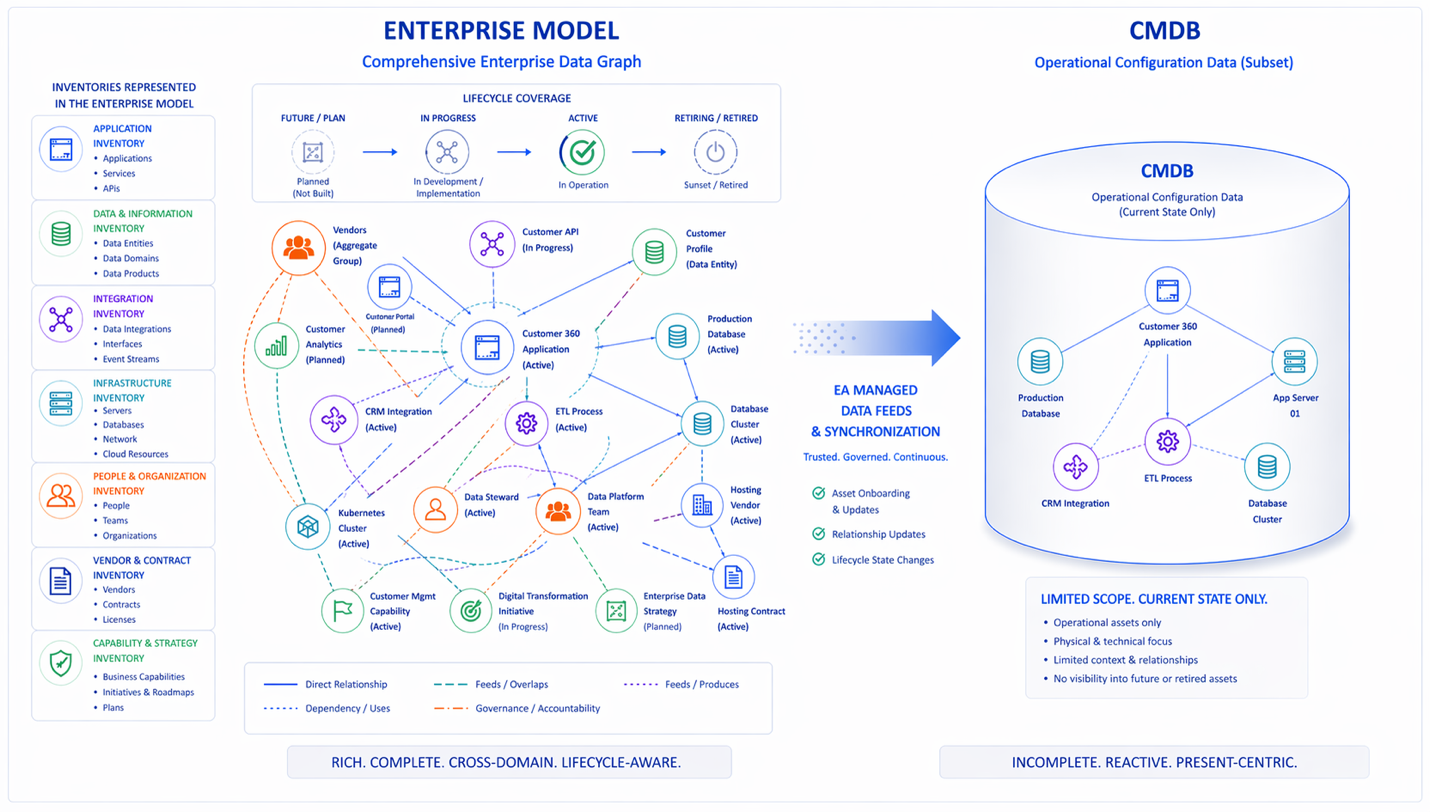
In this model, Architecture continues to own the Enterprise Model and maintains it as the authoritative source of truth for the asset inventory and the logical relationship layer. On a defined schedule — nightly, weekly, or event-triggered when significant changes are made — the Enterprise Model pushes its asset and relationship data downstream to the CMDB. The CMDB becomes a consumer of the Enterprise Model rather than an independent source. It receives the CI records and relationship mappings that Architecture has defined, in the schema and taxonomy that Architecture governs, at the quality level that Architecture maintains.
Operations teams continue to contribute the operational layer data that only they can provide: configuration states, patch levels, availability records, incident associations, and the physical asset data that auto-discovery tools surface. These contributions layer on top of the architectural foundation that the synchronization provides. The result is a CMDB that combines Architecture’s completeness and accuracy on the logical layer with operations’ currency and depth on the operational layer — the best of both functions, without requiring either to cross into territory where the other has a natural advantage.
The synchronization model also makes the gap between the two representations visible and manageable. When the Enterprise Model contains an asset that the CMDB does not, the synchronization surfaces it. When the CMDB contains an asset that the Enterprise Model does not — typically a physical asset discovered by auto-discovery tools that has not yet been reviewed by Architecture — the delta is flagged for architectural review. The two models are no longer allowed to drift in silence. Divergence becomes detectable, actionable, and over time, eliminable.
The synchronization approach also sets the stage for full ownership transfer when organizational conditions permit. Once Architecture has established the authoritative schema, the governed synchronization, and the quality baseline for the logical layer, the case for formally transferring CMDB ownership to Architecture is straightforward: the work is already being done by Architecture, the model is already being governed by Architecture, and the only remaining question is whether the organizational chart should reflect the reality of where the knowledge and the accountability actually reside.
What Architecture Gains
Taking ownership of the CMDB — or establishing the synchronization model — gives Architecture something that architecture documentation alone rarely provides: a direct, visible, and indispensable role in the day-to-day operational management of the technology estate.
CMDB data is consumed continuously by the processes that keep the enterprise running: ITSM workflows, change management approvals, incident response investigations, compliance audit responses, capacity planning exercises, and vendor contract reviews. These are not occasional or strategic activities. They happen daily, across the organization, at every level from front-line operations to the board. An Architecture team that owns the data these processes depend on is not a team that produces documents. It is a team that the enterprise cannot function without.
This is the same organizational leverage argument that drives the other articles in this series. The at-risk architecture practice makes Architecture indispensable by delivering results where they matter most — in the initiatives most likely to fail. Taking ownership of enterprise process automations and the service catalog makes Architecture indispensable by owning the infrastructure of how IT delivers services. Taking ownership of the CMDB makes Architecture indispensable by owning the model that every operational process in the enterprise draws from when it needs to understand what exists and what depends on what.
There is a compounding benefit as well. An Architecture team that owns both the Enterprise Model and the CMDB has a feedback loop that neither function has in isolation. Changes observed in the operational layer — new assets discovered by auto-discovery tools, configuration drifts detected by monitoring, incidents that reveal undocumented dependencies — flow back into the Enterprise Model, improving its accuracy. Changes made in the Enterprise Model — new assets planned, relationships updated, future-state designs formalized — flow forward into the CMDB, improving its completeness and currency. The two models reinforce each other rather than competing with each other. The enterprise gets a single, continuously improving model of its technology estate rather than two diverging approximations that neither team fully trusts.
Closing Thought
The CMDB failure pattern is one of the most consistent findings in enterprise technology management. It has played out at Merrill Lynch, at major life sciences and pharmaceutical companies, at financial services firms, at healthcare organizations, at defense contractors, and at technology companies. The platform changes. The scale changes. The specific gaps and inaccuracies change. But the root cause is the same everywhere: an artifact designed to model the enterprise has been given to a team that is not positioned to model the enterprise, while the team that is positioned to do exactly that — and is already doing it, upstream, more completely and more accurately — has been left out of the ownership conversation.
Enterprise Architecture should own the CMDB. Not because it would be convenient, or because it would make Architecture more powerful, but because Architecture is the function with the knowledge, the lifecycle position, the organizational scope, and the modeling discipline to maintain a CMDB that actually works. When Architecture owns it, the CMDB becomes an extension of the Enterprise Model rather than a competing approximation of it. The logical layer gains the accuracy and completeness it has never had under operations ownership. The operational processes that depend on the CMDB gain a foundation they can actually trust. And Architecture gains the organizational role it has always deserved: not a function that produces documents about the enterprise, but a function that maintains the model the enterprise runs on.
If full ownership transfer is not immediately achievable, establish the synchronization. Make the Enterprise Model the authoritative source for the CMDB’s logical layer, and make the gap between the two visible, measurable, and shrinking. The destination is the same either way: a single, Architecture-governed model of the technology estate that serves both the strategic needs of planning and the operational needs of execution. The only question is how quickly you get there.
Published by Guerino Enterprises, LLC – Copyright Guerino Enterprises & Frank Guerino