Data Compilation and Data-Driven Synthesis
NOUNZ is a data compiler I designed and built to research and verify the use of a paradigm called Data Driven Synthesis (DDS) for the generation of large-volume data graphs. This included comprehensive richly described nodes and massive quantities of reified 5-tuple relationships. The effort was so successful that the compiler was expanded to automatically build (i.e., synthesize) other important data, information, and knowledge management constructs like massive static websites, taxonomies, ontologies, data fabrics, and much more.
Author: Frank Guerino
Key Terms and Definitions
The terms below are used throughout this document in a specific way. Defining them up front helps clarify the distinction between traditional fixed-schema approaches and Data-Driven Synthesis (DDS).
-
Schema (Data Skeleton): The structural model that constrains and organizes data—analogous to a “skeleton” that determines what kinds of entities and relationships can exist and how they fit together.
-
Inflexible Schema: A schema that is designed up front and then conformed to; once large volumes of data are loaded, changes to the schema become time-consuming, error-prone, and expensive.
-
Flexible Schema: A schema that can be fabricated (regenerated) dynamically from descriptive inputs (data and rules), enabling rapid and repeated structural change as the underlying data evolves.
-
Flexible Schema Modeling (FSM): The working paradigm described in this paper where the schema (the “skeleton”) is treated as something that can be repeatedly regenerated from descriptive data, rather than something fixed.
-
Synthesis: Automated construction of a target structure from a description; in the chip industry, HDLs are used to synthesize circuits—this paper applies the analogy to synthesizing data structures from data.
-
Data-Driven Synthesis (DDS): The process of creating things (including skeletons/schemas) from the data, where a compiler consumes data (and rules) and generates structures from it.
-
Data Compiler: A compiler that takes data (structured, semi-structured, and potentially unstructured) plus rules, and then builds/synthesizes useful structures and artifacts from that input.
-
Data Graph (DG): A graph synthesized from data and rules, composed of Nodes and meaningful, described relationships between nodes.
-
Node: A specific instance of a thing (a “noun”) represented in the graph, typically described by direct traits (fields) and connected to other nodes through relationships.
-
Semantic Relationship (SR): A relationship that carries explicit descriptive meaning (in plain-English terms) about how two nodes are related.
-
Tuple (2-tuple, 3-tuple, 5-tuple): The number of components used to express a relationship. Higher-arity tuples (e.g., 5-tuples) can encode richer meaning than simple 2-tuple links.
-
5-tuple (Reified) Semantic Relationship: The core relationship form used here: (1) Source Node Data Type, (2) Source Node Identifier, (3) Predicate, (4) Target Node Data Type, (5) Target Node Identifier.
-
Predicate: The descriptive relationship label that explains the nature of the connection between nodes (e.g., “Spouse,” “Resident Of,” “Product Owner”).
-
Knowledge Graph (KG): A graph used for knowledge representation and reasoning; in this paper, richer DGs and SRs are positioned as foundations for creating richer KGs than simple link graphs.
Background and Overview
By the time I left working directly for corporations to build my own practice, I had spent a significant portion of my career both purchasing and building complex and expensive systems that existed to allow the loading of data into representative relational graphs with the intent to query and understand data, both through its direct traits (i.e., its descriptive fields) and its indirect traits (i.e., relationships). The goals were always to use such systems to help IT organizations and their business perform functions like impact analysis, what-if modeling, root cause analysis (RCA), anomaly detection, risk or threat detection, and much more.
Back then, graph databases were just evolving, and these systems were built with fixed relational models that mimicked data graphs (i.e., nodes and relationships), which made them slow, difficult, and expensive to feed with data, maintain, use, and especially change. Even worse, the user interfaces were highly limited in their capabilities, further limiting what enterprises could do with their data without additional investments to build and maintain ancillary ecosystems of reporting and analysis tools—all to try to make the data more usable than the expensive tools that were originally purchased on promises that they would do things they never could.
Common examples of such tools were Enterprise Architecture Modeling Tools (EAMTs) and Configuration Management Databases (CMDBs). All these tools had major limitations in their underlying relational schemas that limited users to predefine fixed meta-models that became almost impossible to maintain and change once large quantities of data had been loaded. They slowly (and sometimes very quickly) became bloated, very expensive, complicated, and, unfortunately, rather useless. The proof is that almost all enterprises admit to getting little value from these tools when compared to the investment it takes to build them out and keep them populated with fresh data. For example, virtually all large enterprises buy into enterprise architecture modeling tools but usually disinvest from them after just a few years of use, claiming little value. CMDBs tend to survive, but the promise of their value is always far greater than reality, as you’ll never hear a business tell you their CMDB is a critical Tier-1 application.
The Problem: Inflexible Schemas
When analyzing the problem, it became clear that the underlying relational schematics (schemas) for these systems were what we call an Inflexible Schema. You design your relational model (or meta-model) and then you conform to it, only changing it when absolutely needed because changing the schema was time-consuming, often complicated, fraught with errors, and very expensive. Anyone who’s ever gone through the process of changing relational tables—and the relational data that’s already loaded into them—and conforming with the design of large and complex relational models understands the pain, effort, and cost of doing so. In fact, most companies moved away from building and maintaining their own custom systems, as the complexities of such systems drove up their costs.
Furthermore, anyone who has managed systems that change over long periods of time understands that the schemas such systems started with became entirely different structures as they evolved. In other words, the schemas change, whether we like it or not, to meet the needs of the evolving business. A metaphorical example would be starting with the skeleton of a dog and changing it, over time, into the skeleton of a humpback whale—where you need to change bones and all the organs and flesh around it manually and incrementally over time—assuming you have the large sums of money to make it happen.
The schema of such systems (i.e., the skeleton) is fixed, difficult, and expensive to change—that is, an Inflexible Schema. Such schemas mean you design your skeleton (i.e., your model or meta-model), you build it, and only after it’s built can you start to populate it with data. Once you do, you’re fully invested in that skeleton (relational model) because of how difficult, time-consuming, and expensive it is to change.
These problems become even more exacerbated when working in an environment where the data is constantly and rapidly changing—both in its values and, more importantly, in its skeletal structures.
Enter the Flexible Schema
An example of where large volumes of data constantly change skeletal structures is the computer chip design and manufacturing industry for Application-Specific Integrated Circuits (ASICs). This industry uses a concept I describe as Flexible Schema Modeling (FSM). In this industry, they use Hardware Descriptive Languages (HDLs) that compile down to massive circuits that get vetted and then manufactured as chips. In other words, they don’t literally draw schematics; they let computers draw them from the descriptions in the HDLs. You describe your circuit in a specific HDL (e.g., VHDL or Verilog), and you use a compiler to synthesize the circuit design from the human-descriptive words in the HDL.
Before ever getting close to manufacturing, any given circuit is changed through descriptions in the HDL thousands, hundreds of thousands, and even millions of times. The pattern is a continuous loop (just like software coding) where:
-
you describe what you want in the HDL,
-
the HDL compiler compiles it down to a logical circuit schematic,
-
you then test and vet the circuit with simulations and emulations where bugs/defects are found,
-
you go back to the HDL and change it to fix the bugs/defects
-
and only when everything passes, do you move on to manufacturing a physical chip (because it’s VERY expensive to do so).
Steps 1 through 4 are repeated over and over until you can manufacture the chip with a high level of confidence that it will be stable for mass production.
Steps 1 through 4 are often repeated thousands, hundreds of thousands, and possibly millions of times.
This paradigm of iterative working in a manner where the data drives the circuit highlights a very important point. The descriptive data in the HDL is the real value, not the resulting logical circuit because the circuit can always automatically be regenerated by its description (i.e., its data and information). This working paradigm highlights that the schematic is and needs to be flexible, such that it can change with the data. I call this data-driven regeneration of data skeletons (i.e. relational models) the Flexible Schema model. In short, the skeleton or schema is fabricated dynamically from the data. The chip design industry calls this construction of flexible schemas from HDLs synthesis.
Introduction to Data Compilers
In the chip design industry, they have HDL compilers that compile language (data & information) into circuits.
In the software design industry, they have software compilers that compile language (data & information) into software applications.
Both these cases use predefined programming languages as the means for describing what you want to build.
-
HDLs like Verilog and VHDL allow us to describe circuits for compilers that synthesize circuits.
-
Software development languages like C, C++, Java, and others allow us to describe applications for compilers that will synthesize the executable application.
Data-Driven Synthesis (DDS) is the process of creating things (including skeletons or schemas) from the data. It operates at a level that is even lower than software languages, where data is presented to a compiler and the compiler creates structures from it.
The type of compiler that can take data, in structured, semi-structured, or unstructured forms, is called a Data Compiler. Imagine feeding repositories of data or spreadsheets into such data compilers and directing them to build things from the data. Then imagine the data changes, and the compiler builds something totally new and different. Finally, imagine this process repeating itself millions of times. This can only happen when working with flexible schemas because fixed schemas cannot handle such rapid and complex change.
The NOUNZ Data Compiler to Test Flexible Schemas
In 2007, I started to design and build a data compiler to automatically synthesize data graphs from data (and rules). This project-turned-product was called NOUNZ—a play on the word nouns, which is a plain-English synonym for the engineering term nodes.

The NOUNZ data compiler was designed to test the creation of massive Data Graphs composed of rich Nodes and large volumes of 5-tuple Semantic Relationships, from nothing but data and configurable rules. It worked.
But the real power showed itself in understanding the value of working with Flexible Schemas. It meant that large complex structures could be torn down and rebuilt to include very complex changes with little effort, very rapidly, and with very little cost.
Imagine describing a building in words (i.e., data), then building it (i.e., synthesizing it) in fractions of a second, walking its floors to make sure you like the layout, then tearing it down in fractions of a second because you don’t like it, then describing complex changes to the building in words, then rebuilding it in fractions of a second, then walking its floors again to test it, then tearing it down again, and repeating this process over and over until you’re happy with the final building—because the entire process is simple, fast, and has negligible cost. This is the power of Data-Driven Synthesis (DDS) and flexible schemas.
With the iterative improvements to the NOUNZ data compiler to improve the richness of generated Data Graphs came the realization that such data compilers can be used to build more than just Data Graphs.
What the NOUNZ Data Compiler Synthesizes
Simply put, NOUNZ is a Data Compiler. It takes in data (structured and semi-structured) and rules, and it builds things.
The first things NOUNZ was trained to build were Data Graphs (DGs), consisting of richly described data Nodes represented by data records that described specific instances of things (i.e., Nouns) and reified 5-tuple Relationships between such nodes.
These 5-tuple relationships later became the foundations for synthesizing more advanced semantic sentences. In other words, the synthesis of reified relationships further allowed the synthesis of descriptive semantic sentences that use such 5-tuples as their foundations. In simpler terms, this means that a multi-component relationship, consisting of five components in this case (i.e., a 5-tuple), can help describe the details of how and why different nodes of different or same specific data types were tied together.
The core data structure of the synthesized 5-tuple relationships is as follows:
-
Source Node Data Type
-
Source Node Identifier
-
Descriptive Predicate (a.k.a. Predicate)
-
Target Node Data Type
-
Target Node Identifier
While the synthesized sentences seem crude when compared to a rich language with a rich grammar, they provided more than enough sentence structure to provide very clear descriptive meaning. For example:
-
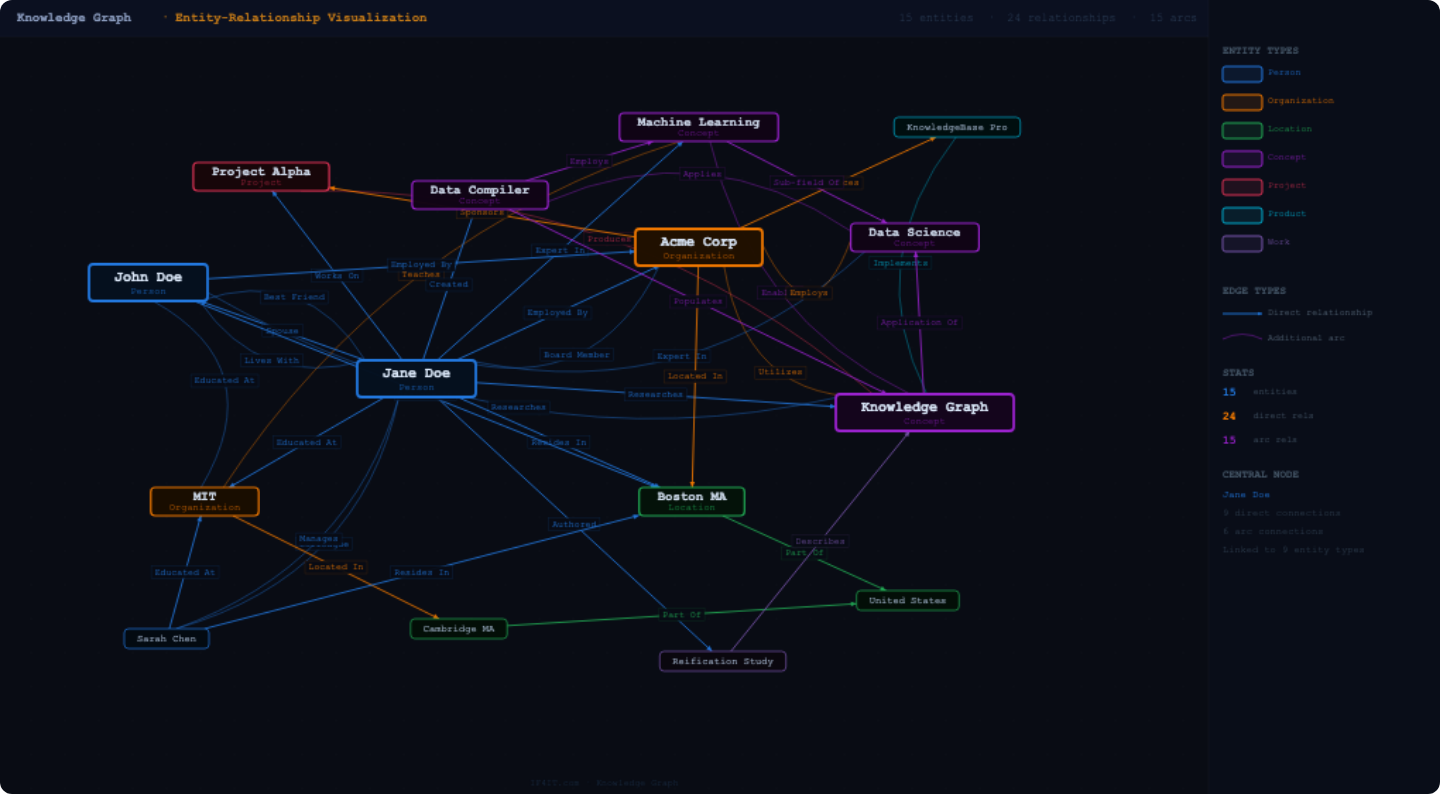
“Person” “Jane Doe” is related as a “Spouse” to “Person” “John Doe.”
-
“Person” “Jane Doe” is related as a “Product Owner” to “Product” “Product Name XYZ”
-
“Person” “Jimmy Doe” is related as a “Child Of” to “Person” “Jane Doe.”
-
“Person” “Jane Doe” is related as a “Resident Of” to “Address” “131 Plain St, Lee, MA 01238.”
-
“Person” “John Doe” is related as a “Resident Of” to “Address” “131 Plain St, Lee, MA 01238.”
Each example above is what is called a Semantic Relationship (SR) and highlights 5 separate descriptive traits (tuples) of the reified relationship. For example:
-
Source Node Data Type = “Person”
-
Source Node Identifier = “Jane Doe”
-
Predicate = “Product Owner”
-
Target Node Data Type = “Product”
-
Target Node Identifier = “Product Name XYZ”
The Importance of Tuples to Semantics
As you read through the above sentences, it might become obvious that a 5-tuple seems to be the minimum viable reified relationship required to create a truly meaningful sentence; what Computer Scientists chasing Artificial Intelligence often refer to as a Semantic Sentence.
For example, a 2-tuple relationship (“Jane Doe”, “John Doe”) tells us Jane Doe is related to John Doe, but it tells us nothing about how they’re related or the deeper meanings of “Jane Doe” and “John Doe.” In fact, while the human mind automatically jumps to the inference that Jane and John are people, Jane could be someone’s pet cat and John could be someone’s pet dog—making the human inference that they were humans not just wrong, but doubly wrong. If we expand the relationship to a 3-tuple like (Jane Doe, Lives With, John Doe), we have confirmation of co-existence, but we still have no clarity on whether Jane and John are humans. We think they are (people), but we don’t absolutely know for sure, as they can be a cat and dog. Such confirmation of deeper facts is critical for computers, where inference can lead to very costly business mistakes.
However, in designing the NOUNZ data compiler, it was discovered that each component or element of a tuple (e.g., X,Y, or Z in the tuple: “(X,Y,Z)”), could not just be random data identifiers or traits. They must have specific intent, which is why it was decided to reify the Data Type that is tightly coupled with and gives meaning to each unclassified Node Identifier (a.k.a. Data Node).
The Utilization of Rich Data Graphs for More Complex Structures
In designing the 5-tuple Semantic Relationships generated by NOUNZ it was confirmed that very large, complex, yet meaningful data graphs could be synthesized from static structured and semi-structured data sets. Each Node could be described by its descriptive traits and each Semantic Relationship brought English sentence descriptions and meaning to the relationships between Nodes.
The question then became: “So, what are we going to do with all these large Data Graphs composed of massive quantities of data rich Nodes and Semantic Relationships?”
Data Graphs, by themselves are certainly powerful for putting into databases and using expensive tools and technologies to query (i.e., ask) questions of. But what if you don’t have access to such expensive tools? Most small companies certainly don’t.
For those new to Graph Theory, Data Graphs are relatives of Knowledge Graphs in the Knowledge Management industry and it quickly became obvious that NOUNZ synthesized Data Graphs could be used to create very large complex Knowledge Graphs… in just seconds or minutes.
The most famous knowledge graph in the world is most likely Wikipedia, which is a massive network of unstructured (at best loosely structured) articles that are linked to each other through human-created-and-maintained HTML links. Each article page is composed of many strings (words, phrases, sentences, paragraphs, etc.) that help compose the full article. Some of the strings are turned into links, making them nodes in the knowledge graph, and each HTML link is an undescribed relationship to another article page. The Wikipedia relationship is, more precisely, a 2-tuple relationship in the form of an HTML link between (1) a string and (2) an article; denoted in tuple notation as “(String, Article).”
For example, the string “George Washington” in an article about U.S. presidents is related through a generic and undescribed HTML link to an article about George Washington. The 2-tuple relationship looks as follows:
- (Unclassified string “George Washington”, Unclassified article page titled “George Washington”)
Our human brains know “George Washington” was a U.S. president because he appeared in article about presidents and we learned he held that office, while “Martha Washington” might have appeared in the same article with a link to her own page. A computer, unlike a human, needs much more to infer why she was on a U.S. presidents’ Wiki page and that she was never a president.
Understanding the 2-tuple architecture of Wikipedia relationships helps one better understand how richer Data Graphs, such as those synthesized by the NOUNZ compiler, create richer and therefore more meaningful Knowledge Graphs. 2-tuples tell us very little about how and why things are tied together, but grander tuples (e.g., 5-tuple) expand our knowledge of how and why.
Data-Driven Synthesis of Grander Knowledge Structures
Once it became clear that the compiler could repeatedly synthesize large Knowledge Graphs with ease, speed and little cost, it became evident that the difficult work was already done and that the synthesis process could easily automatically build even more advanced Flexible Schema constructs. For example:
-
Dynamic and fully explorable charts, graphs, and complex visualizations for knowledge exploration and learning.
-
Endlessly-Nested-Taxonomies for organizing and categorizing.
-
Highly consistent and interwoven Ontologies for Data Fabrics and A.I. Large Language Model (LLM) training.
-
Massive static read-only Wikis for knowledge sharing and learning
-
Enterprise Models (EMs) and Large Volume Enterprise Models (LVEMs) for Impact Analysis, Root Cause Analysis (RCA), Cause and Effect Analysis (CEA), What-If modeling, question answering (Query/Response), Risk/Threat Detection, and much more.
-
Preconstructed data objects that can be auto-generated for integration with other systems that require specific data formats and structures
-
and more.
Conclusion
Systems that are designed or come with pre-fixed schemas (i.e., inflexible schema solutions) offer little flexibility, take a tremendous amount of effort and time to feed, maintain, and change, and come with very high investment and maintenance costs.
Unlike traditional Inflexible Schema solutions, Flexible Schema solutions like data compilation and data-driven synthesis offer enterprises very high levels of flexibility, speed, lower complexity, and more advanced data richness—at a much more affordable cost.
Published by Guerino Enterprises, LLC – Copyright Guerino Enterprises & Frank Guerino